)
Event organizers and participants experience a variety of emotions during the lifecycle of an event: excitement, anticipation, stress, and sadness when it’s over. OpenDev: Large Scale Usage of Open Infrastructure was no exception. To be honest, baby Yoda put it best.

This week, the OpenStack Foundation (OSF) held its third OpenDev conference. This iteration focused on scaling challenges for open infrastructure across a variety of topics including upgrades, high availability (HA) networking, bare metal, and more. Jonathan Bryce, OSF executive director, kicked off the event explaining how OpenDev events are an example of how the global Open Infrastructure community collaborates without boundaries. He encouraged participants to think broadly and remember that collaboration is built by people who are actively engaged and participating by sharing their knowledge and experiences so they can learn from each other.
This virtual event recruited participants from over 70 countries who spent three days asking questions, sharing scaling challenges, and explaining implementations that worked for their local environments. Each moderated session combined various perspectives on the challenges, questions for how to improve, and next steps that the community can collectively collaborate on to ease these operator challenges.
Thanks for all those involved in organising #OpenDev2020 from the chairs, track organisers and the OSF staff. Having a few hours each day remotely worked well but I missed the F2F too. pic.twitter.com/XQ8UlAmqMl
— Tim Bell (@noggin143) July 1, 2020
Thank you to the OpenDev: Large-scale Usage of Open Infrastructure Software programming committee members: Beth Cohen, Roman Gorshunov, Belmiro Moreira, Masahito Muroi, and Allison Price. You helped to make these discussions possible!
So, what happened? Below is a snapshot of the conversations that took place, but I want to encourage you to check out the event recordings as well as the discussion etherpads found in the OpenDev event’s schedule to join the discussion.
Jump to the User Stories recap
Jump to the Upgrades recap
Jump to the Tools recap
Jump to the HA Networking Solutions recap
Jump to the Software Stack recap
Jump to the Bare Metal recap
Jump to the Edge Computing recap
Jump to the OpenDev event’s next steps
User Stories
Ahead of the weeks’ discussions, speakers from Blizzard Entertainment. OpenInfra Labs, and Verizon shared their own scaling challenges via short user story presentations Monday morning followed by audience questions moderated by Mark Collier, OSF COO.
Colin Cashin, Blizzard Entertainment senior director of cloud engineering, and Erik Andersson, Blizzard Entertainment technical lead, senior cloud engineer, discussed four key scaling challenges that affect their 12,000 node OpenStack deployment that spans multiple regions. Their challenges were: Nova scheduling w/ NUMA pinning, scaling RabbitMQ (a frequent challenge repeated throughout the week), scaling Neutron, and compute fleet maintenance. The Blizzard team received a flurry of questions about their specific challenges and their multi-cloud approach (OpenStack, Amazon, Google, and Alibaba). They also used the opportunity to share that they’re hiring engineers to help manage their massive OpenStack footprint, so if you’re interested, check out their openings.

Michael Daitzman provided an overview of OpenInfra Labs, the newest OSF pilot project, that is a collaboration among several research institutions including Boston University, Harvard University, MIT, Northeastern University, and University of Massachusetts. He covered some challenges for integrating different open source technologies into a single environment including specific problem areas like monitoring and what happens when your Ceph clusters aren’t properly backed up (TL;DR: you lose all your data).
Beth Cohen, OpenDev veteran and moderator of the HA networking solutions discussion, presented an updated Verizon case study centered around some of their challenges. Her team is seeing that application configuration (written by partners) has a significant effect on how the applications behave in the environment (i.e. w/ encryption turned on, throughput halved). With traffic going through all of these systems, it can be hard to identify the source of the problem. In order to isolate and reproduce this, they have built a full production engineering lab with full testing capabilities that is also used by their development team, ultimately providing a really nice feedback loop.
Upgrades
When asking OpenStack operators their number one challenge with their deployments, upgrades are often at the top of the list. This discussion, moderated by Belmiro Moreira, cloud architect at CERN, explored the different setbacks around upgrades, including why operators find them so daunting. Top reasons shared included upgrading across versions, the amount of resources needed, the feeling of “once you’re behind, you’re behind,” and API downtime. Some suggestions included the recent pre-upgrade checks that the OpenStack TC set as a goal in the Stein cycle in 2019 as well as fast forward upgrades.
As can be expected, this session included a lot of discussion about specific upgrade scenarios. One of the next steps that Jonathan mentioned in the event wrap-up was the opportunity to use the OpenDev event as a launching off point for some upgrade documentation. If you’re an operator who has successfully upgraded your OpenStack environment and would like to collaborate on a set of tips, please sign up here.
Tools
Moderated by John Garbutt, principal engineer at StackHPC, the Tools discussion covered a few topics: Different ways to measure scale, the different considerations into what you’re trying to scale and how that will affect tools, and finding and removing bottlenecks, which is naturally where a lot of the conversation centered. Shared challenges included RabbitMQ flatlining, legacy Keystone UUID tokens, and losing access to Cinder volumes.
The next step for this topic was largely centered around sharing tooling, which included the idea of revisiting the OsOps initiative that was started a few years ago so that operators could share tooling with each other and collaborate more closely.
HA Networking Solutions
What does HA mean from a network perspective? Are you concerned with networking connectivity failures in your environment and if so what are you doing about them? Do you have a diverse network? Beth Cohen, cloud product technologist at Verizon, started the discussion with these questions to make sure that everyone knows what networking high availability means in this context and get to know how important HA is in the participants’ deployments.
Later, the participants dived into discussions around different factors that apply to scaling, where you put failure domains and what the most cost-effective way is to do that. Should we pay for a lot of redundant and expensive hardware or handle failure at the rack level, and trust the software to be able to work around that? The interactive discussion continues. If you are interested in adding your thoughts to the etherpad, please add it here.
Software Stack
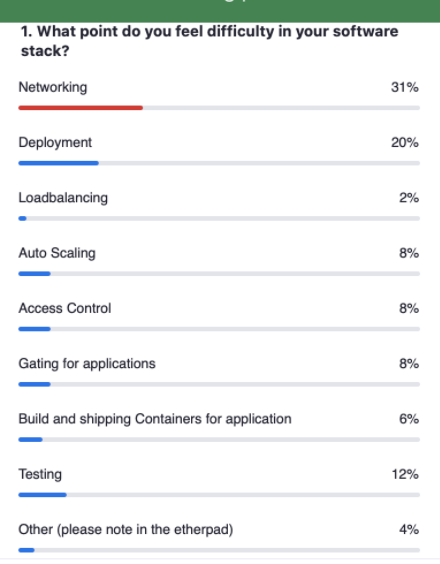
The Software Stack discussion, moderated by Masahito Muroi, senior software engineer at LINE Corp., centered around what the open source mix will be over time and how to plan for deployment infrastructure software and the resources that the end users will want. A poll during this session helped show that networking and deployment were the two biggest challenges that participants faced.
Bare Metal
James Penick, architect director at Verizon Media, moderated an active discussion around bare metal, including multiple opportunities where he activated his own team to implement learnings back in their own environment. The conversation included use cases for bare metal and where participants see those use cases evolving to, including scenarios like 5G, the tooling required around bare metal management, and lifecycle management. With only an hour available for discussion, participants were only able to scratch the surface on the bare metal conversation, but luckily, the next OpenDev event (Hardware Automation, July 20-22) will be centered around this topic, including an entire day on lifecycle management.
Edge Computing
The last session of the event was around the edge computing use case and was moderated by Shuquan Huang, technical director at 99cloud. The discussion kicked off with use cases that included farming, high performance computing (HPC), 5G, facial recognition, and an impressive China Tower edge computing use case that was planning to leverage StarlingX across 2 million antenna towers in China. The different architectural requirements for the varying edge use cases was a popular question and unsurprising as participants had earlier identified networking as their number one pain point in the Software Stack discussion. This was a good opportunity to promote the OSF Edge Computing Group’s latest whitepaper, Edge Computing: Next Steps in Architecture, Design, and Testing.
Next Steps
The goal with the OpenDev events is to extend this week’s learnings into future work and collaboration, so Jonathan Bryce and Thierry Carrez, OSF VP of Engineering, wrapped up the event to discuss next steps. These include:
- Join the OpenStack Large Scale SIG to continue sharing challenges and solutions around scaling
- Take the OpenStack User Survey to share feedback with the upstream community
- Collaborate on documentation around common pain points, like upgrades
- Revive OsOps Tools
- Join the OpenDev: Hardware Automation event to continue discussing bare metal use cases
- Check out OpenInfra Labs and get involved in their mission to refine a model for fully integrated clouds supporting bare metal, VMs, and container orchestration.
Let’s keep talking about open infrastructure! Check out the next two OpenDev events:
- Hardware Automation, July 20-22, 2020
- Containers in Production, August 10-12, 2020
- Revolution in Cloud Economy: How FishOS – Integrated Solution Reduced Enterprise’s Cloud Costs by 50% - July 1, 2024
- Inside Open Infrastructure: June 2024 - June 18, 2024
- 2024 Superuser Awards Nominations Now Open - June 9, 2024









