)
OpenInfra Live is a new, weekly hour-long interactive show streaming to the OpenInfra YouTube channel every Thursday at 14:00 UTC (9:00 AM CT). The upcoming episodes feature more OpenInfra release updates, user stories, community meetings, and more open infrastructure stories.
This week’s OpenInfra Live episode is brought to you by the experts from the OpenStack community, discussing their stories of upgrading in large scale OpenStack infrastructure.
Keeping up with new OpenStack releases can be a challenge. At a very large scale, it can be daunting. In this episode of OpenInfra.Live, operators from some of the largest OpenStack deployments at Blizzard Entertainment, OVH, Bloomberg, Workday, Vexxhost and CERN will explain their upgrades methodology, share their experience, and answer questions from our live audience.
Enjoyed this week’s episode and want to hear more about OpenInfra Live? Let us know what other topics or conversations you want to hear from the OpenInfra community this year, and help us to program OpenInfra Live!
Key Takeaways
Upgrading OpenStack at Blizzard Entertainment
Joshua Slater, Cloud Systems Engineer at Blizzard Entertainment, shared five of their practices on how they upgrade OpenStack which powers all of the games at Blizzard Entertainment. These five practices are “build a container for every service”, “have 8-hour maintenances every week”, “stick to a rigorous upgrade schedule”, “remove your cloud customers’ favorite service”, “enroll in medical school for database administrators”.
Question from the Live audience:
- What are some scaling challenges that Blizzard faces? Since the player’s usage increases dramatically with game releases.
- “Most of our fleet was already deployed prior to Nova Cells, so as we add more compute nodes into high volume regions it has put a lot more pressure on the single RabbitMQ cluster that is handling all the computes for that region. Consequently, we have needed to get good at RabbitMQ tuning and performance. Having multiple regions in a data center site was part of our original design to spread that load. We have not yet decided on how we would transition our current live compute deployment to take advantage of the Nova Cells feature.”
How OVH Cloud Upgrades OpenStack
Arnaud Morin, DevOps at OVH Cloud, kicked off his presentation by giving an overview of what a typical OpenStack deployment looks like.

Transitioning to how teams at OVH Cloud upgrade OpenStack, Joshua explained why they need to upgrade, what they want to achieve when they upgrade as a public cloud provider, and their strategy to solve the challenges they are facing.
Questions from the live audience:
Upgrading OpenStack at VEXXHOST
“…We focus on running upstream as much as we can… By leveraging upstream code, it allows us to take advantage of the testing done by OpenStack to avoid working about your upgrade path being broken,” said Mohammed Naser, Founder & CEO at VEXXHOST.
By also leveraging Kubernetes as a base platform for their deployments, it allowed them to start deploying clouds at a much faster rate.
OpenStack Upgrade Story at Workday
Imtiaz Chowdhury, Principal Software Development Engineer at Workday, kicked off his presentation by defining what OpenStack upgrade entails at Workday and providing three constraints they face. The diagram below shows what their upgrade strategy looks like at a high level.

How Bloomberg Does It
“The technology that we use vaires. It’s the opposite of Mohammed’s strategy (which) is all containerized. We just install OpenStack on machines, and then upgrade in place,” said Chris Morgan, Team Lead of Bloomberg Clustered Private Cloud services team. With a different strategy on upgrading, Chris gave a brief overview of what challenges they face and what solutions they’ve implemented.
Upgrading OpenStack at CERN
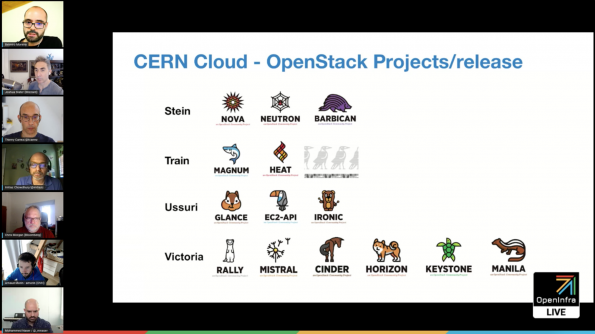
With almost 300k core and 7k bare metal notes, team at CERN Cloud is no stranger to OpenStack upgrades. Belmiro Moreira, Cloud Engineer at CERN, briefly introduced 15 OpenStack projects that are running at CERN and their upgrade considerations.
Next Episode on #OpenInfraLive
Don’t merge broken code. Infrastructure at scale relies on quality software that is tested before it’s deployed. Operators rely on open source CI systems like Zuul for gating, scaling across organizations and cross-project dependencies. In this #OpenInfraLive episode, Jim Blair, Zuul Maintainer and CEO at Acme Gating, and Mohammed Naser, CEO of Vexxhost will provide an overview of Zuul, the open source CI/CD business case and a demo showing what cross project dependencies look like in production.
Tune in on Thursday, May 27 at 1400 UTC (9:00 AM CT) to watch this OpenInfra Live episode: Large Scale Open Source CI Featuring Zuul
You can watch this episode live on YouTube, LinkedIn and Facebook. The recording of OpenInfra Live will be posted on OpenStack WeChat after each live stream!
Like the show? Join the community!
Catch up on the previous OpenInfra Live episodes on OpenInfra Foundation YouTube channel, and subscribe to the Foundation email marketing to hear more about the exciting upcoming episodes every other week!








