)
Check out the previous articles for option one and option two.
Option 3: Growing Clusters Horizontally
This option is by far the least popular despite being very straightforward, as it has a pretty narrowed use case when it makes sense to scale this way.
Though, to preserve quorum you should always have an odd number of cluster members or be prepared to provide extra configuration if using an even number of members.
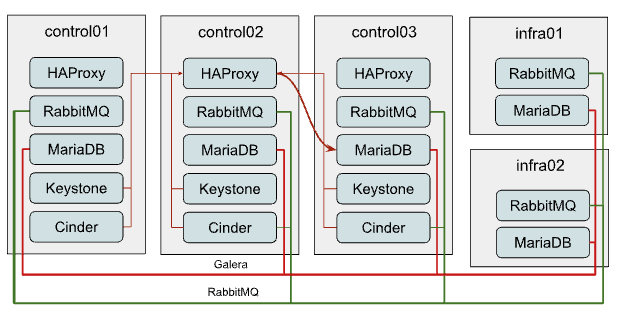
Adding new members to the MariaDB Galera cluster
Horizontal scaling of the MariaDB cluster makes sense only when you’re using an L7 balancer which can work properly with Galera clusters (like ProxySQL or MaxScale) instead of default HAProxy and the weak point of the current cluster is read performance rather than writes.
Extending the cluster is quite trivial. For that, you need to:
1. Add another destination host in openstack_user_config for database_hosts:
database_hosts: control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13 infra01: ip: 172.29.236.21 infra02: ip: 172.29.236.22
2. Create new containers on the destination host:
openstack-ansible playbooks/lxc-containers-create.yml --limit infra01,infra02,galera
3. Deploy MariaDB there and add it to the cluster:
openstack-ansible playbooks/galera-install.yml
4. Ensure the cluster is healthy with the following ad-hoc:
ansible -m command -a "mysql -e \"SHOW STATUS WHERE Variable_name IN ('wsrep_local_state_comment', 'wsrep_cluster_size', 'wsrep_incoming_addresses')\"" neutron_galera
Adding new members to the RabbitMQ cluster
Growing the RabbitMQ cluster vertically makes sense mostly when you don’t have HA queues or Quorum queues enabled.
To add more members to the RabbitMQ cluster execute the following steps:
1. Add another destination host in openstack_user_config for mq_hosts:
mq_hosts: control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13 infra01: ip: 172.29.236.21 infra02: ip: 172.29.236.22
2. Create new containers on the destination host:
openstack-ansible playbooks/lxc-containers-create.yml --limit infra01,infra02,rabbitmq
3. Deploy RabbitMQ on the new host and enroll it to the cluster:
openstack-ansible playbooks/rabbitmq-install.yml
4. Once a new RabbitMQ container is deployed, you need to make all services aware of its existence by re-configuring them. For that, you can either run individual service playbooks, like this:
openstack-ansible playbooks/os-<service>-install.yml –tags <service>-config
Where <service> is a service name, like neutron, nova, cinder, etc. Another way around would be to fire up setup-openstack.yml but it will take quite some time to execute.
Conclusion
As you might see, OpenStack-Ansible is flexible enough to let you scale a deployment in many different ways.
But which one is right for you? Well, it all depends on the situation you find yourself in.
In case your deployment has grown to a point where RabbitMQ/MariaDB clusters can’t simply deal with the load these clusters create regardless of the hardware beneath them – you should use option one and make independent clusters per service.
This option can be also recommended to improve deployment resilience – in case of cluster failure this will affect just one service rather than each and everyone in a common deployment use case. Another quite popular variation of this option can be having just standalone MariaDB/RabbitMQ instances per service, without any clusterization. The benefit of such a setup is very fast recovery, especially when talking about RabbitMQ.
In case you are the owner of quite modest hardware specs for controllers, you might pay more attention to option two. This way you can offload your controllers by moving heavy applications, like MariaDB/RabbitMQ, to some other hardware that can also have relatively modest specs.
Option three can be used if your deployment meets the requirements that were written above (ie. not using HA queues or using ProxySQL for balancing) and usually should be considered when you’ve outgrown option one as well.
- Scaling OpenStack-Ansible Deployment: RabbitMQ and MariaDB – Option Three - August 27, 2023
- Scaling OpenStack-Ansible Deployment: RabbitMQ and MariaDB – Option Two - August 26, 2023
- Scaling OpenStack-Ansible Deployment: RabbitMQ and MariaDB – Option One - August 25, 2023










