)
The total cost of ownership for an OpenStack private cloud can be half of other infrastructure alternatives. The key to achieving such a goal is to capture relevant metrics and watch them closely say the team at Verizon Wireless. At the recent OpenStack Summit Boston, Billy Felton and Andrew Hendrickson of Verizon along with Sanjay Mishra CEO of Talligent offered a look into the platform, its architecture and what’s next as they deal with the challenges of edge computing.
Deploying in hyperscale
Andy Hendrickson, senior manager, Verizon Wireless, offers a look inside the Verizon Cloud Platform (VCP) and shows what’s under the hood, architecture-wise.
“We like to define it as a large-scale cloud. It’s built with OpenStack,” Hendrickson says. He outlines six guiding principles around VCP: Version control, machine readable, no physical configuration, serialization/delivery, declarative and bots.

“VCO is defined by the services, not the tenants. We have to serve multiple customers with this cloud…We need to give our users the ability to quickly deploy and support their applications and multiple lines of business we’re supporting. It’s on-demand and self-service to support the ability to do things in an attended and unattended manner…When we’re deploying at our kind of scale we’re deploying at, we must version control everything,” he adds. Other important features include that everything must be machine readable (documentation, deployment guides), no physical configurations are necessary, and serialization in delivery as much as possible. “This has been a mind shift for us as a deployment organization- declaring everything in advance. So, building out our architectures, declaring those in advance in a place where we can go grab them an actually build them,” he says. The final guiding principal: use bots wherever possible —automation, but also leveraging them to go out and do things and answer questions. “This is a big part of the way that we’re supporting our platform as well,” he says.
Regional architecture
“We haven’t adopted the region zero concept with OpenStack, but we have adopted regions as our minimum mapping unit,” Hendrickson says. Each box in the slide below is actually a region.
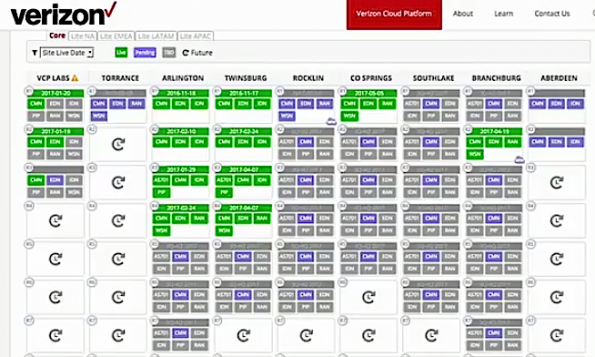
“This current view is just showing the live date – when things are coming online and actually what provider networks we have as part of this. But I can quickly switch persona and look at something like capacity within the same grid.”
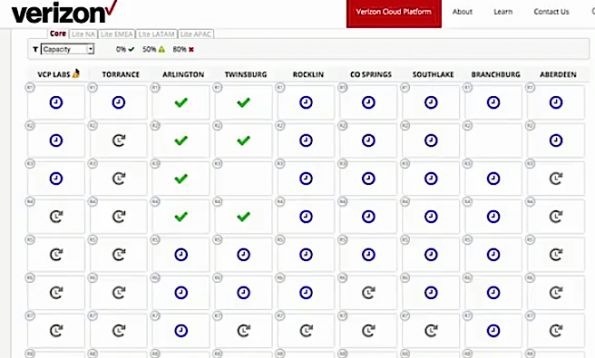
“What we’re looking at is information that’s been drawn from live systems, showing the consumption of our virtual CPUs, our memory, and available bandwidth,” he notes. Regions have become a big part of how we deal with things. We like to refer to it as ‘regional diversity.’
The team has multiple versions of OpenStack running at the same time. “This is how we deal with our upgrade and patching strategy. We have a lot of responsibility falling upon our tenants to move workloads between the different versions of OpenStack that are running. We currently have a destructive mode for doing upgrades where we move workloads from one region to another, we destroy a region and we rebuild it. We are messing around with non-destructive ways of doing this as well in terms of leveraging live migration underneath the hood, but that’s something we’re moving slowly into. We’re not beginning there. It’s real data. It’s live.”
Interesting use case @verizon – Pushing the edges with @OpenStack via #OpenStack #Superuser https://t.co/tzRhoCMnHE #NFV #OpenStackSummit pic.twitter.com/k53etuLuxA
— Kenneth Hui (@kenhuiny) May 17, 2017
“The interesting thing here is anybody can come and get this information. Our illusion of infinite capacity when we’re talking about internal use- there is no illusion. You can see exactly what’s there. You can see how much is left. You see how performant it might be.”
“To solve for this illusion of infinite capacity, we’ve done things like that this that are not necessarily core or part of OpenStack itself. We call them – I don’t know if it’s appropriate, but “second-class citizens” to the platform itself. So we do this in a non-invasive manner so when we deploy and upgrade, we’re not interrupting. We’re not causing a dependency there.”
“This has become paramount for us to be able to support multiple regions, multiple types of orchestration on top.
there’s another unique problem that we needed to solve. Having moved toward that region architecture that I had described was sort of the maintenance for our users of all of the Horizon and services dashboard links and things like that. There’s multiple ways to handle that, but this actually single front end to come in fronting all of those regions that I showed earlier, which by the end of the year will be well over 100. So, this kind of correlates that and collates it together in one places.”
Edging towards the future
Billy Felton, director of technology at Verizon Wireless, offered a look into where they’re headed next. “We’ve really done a pretty good job addressing the perception of infinite capacity. We’ve recognized that we do things differently in a cloud than we’ve done them the legacy networks that we’ve built before.” He admits that the latency aspect of this is “a little bit more of a challenge.”
’@verizon‘s cloud-in-a-box offering based on #OpenStack delivers computing to the edge — and your local coffee shop. https://t.co/82487FaFAQ
— OpenStack (@OpenStack) May 8, 2017
Mobile-edge computing is “kind of the big buzzword running around” where companies are pushing stuff out to the edge of their networks. “One of the first issues I have is been defining what the edge is. Because technically, the edge is defined by where your consumption is – whether that’s at the actual edge of your network or in the core of your network, so it comes down to where you need workload to run to best suit the consumer of that workload wherever that might be.” To solve the issue, he says, look at the behavior of the user. Is the user going to be driving across town? Is the user going to be something that’s another peered machine-to-machine connection that might be co-located in one of your core locations? And what are the application needs. What type of services? Some services are more sensitive to latency than others. It also makes sense to look at workload needs from the perspective of storage, compute, and what’s needed to support that workload. what it all boils down to is you have a spatial problem as well as a logical problem that you have to correlate.”
Certain applications require very low latency – say 5 milliseconds or 1 millisecond- and it makes sense to push that workload to that location where you can defy the speed of light. “As much as we would enjoy it, we still haven’t figured out how to accelerate packets beyond the speed of light,” Felton quips. “Because we can’t do that, there’s only one thing we can do. That’s to change physics.” That changed the formula — moving the workload to the source where it needs to be, through orchestration and container mechanisms, he says. (For more details, check out Beth Cohen’s keynote presentation.) “It’s a challenge for us to solve this — it involves deploying compute resources, storage resources and SDN network resources at a bunch of locations. It’s definitely not an easy problem to solve.”
It’s one of a series of challenges that Felton says they hope to keep solving with OpenStack and the OpenStack community. “The future is bright for us with OpenStack. It’s a core part of our plan moving forward,” he says.
You can catch the 42-minute talk here.
Cover Photo // CC BY NC
- Demystifying Confidential Containers with a Live Kata Containers Demo - July 13, 2023
- OpenInfra Summit Vancouver Recap: 50 things You Need to Know - June 16, 2023
- Congratulations to the 2023 Superuser Awards Winner: Bloomberg - June 13, 2023










