)
Let’s start with the definition of interoperability – “interoperability (between/with something) is the ability of computer systems or programs to exchange information” [1].
That’s quite vague, let’s try to be more exact, here is another definition of interoperability – “Interoperability refers to the ability of apps, equipment, products, and systems from different companies to seamlessly communicate and process data in a way that does not require any involvement from end-users” [2].
OpenStack interoperability is defined as “The goal to help users make informed decisions and adopt the OpenStack products that best meet their business needs. They should be able to easily identify products that meet interoperability requirements via the OpenStack logos, as well as evaluate product capabilities in the OpenStack Marketplace by viewing test results and other technical product details.” [3].
In order to fulfill this goal, the Interop Working Group was formed (back then known as Defcore) in 2014. The group has been maintaining the interop repository since then. The repository contains a set of tests (tempest tests) per a guideline. Historically, guidelines were released twice a year (with every OpenStack release). Later on, the guideline release cadence transitioned to once a year, and recently became update-driven – e.g. new tests were written in Tempest and are now being considered in interop (whether they should become a part of the next guideline or not). Anyway, you can find more information about how IWG operates, what tools it maintains and about the interoperability process as well as different interoperability programs, in this article.
Facts
As Tempest plays a key role in interop testing, let’s check its timeline [4]. Figure 1 shows that Tempest was at its peak in the number of contributions between 2014 (when the IWG was founded) and 2017. Since 2017 the contributions to Tempest have been on the decline.
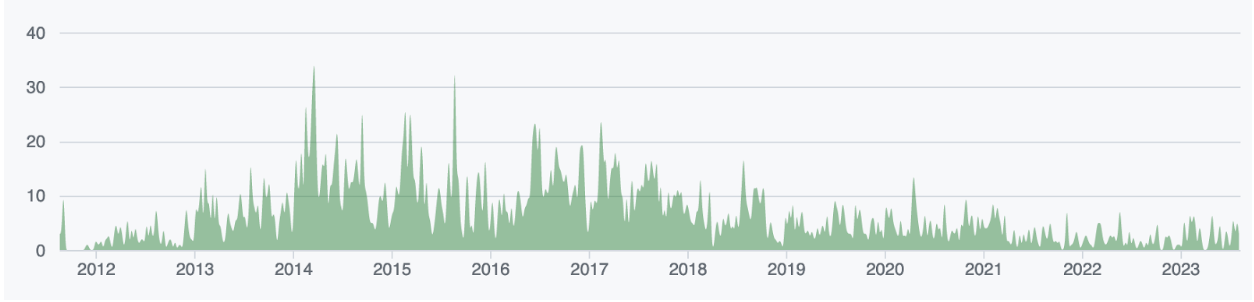
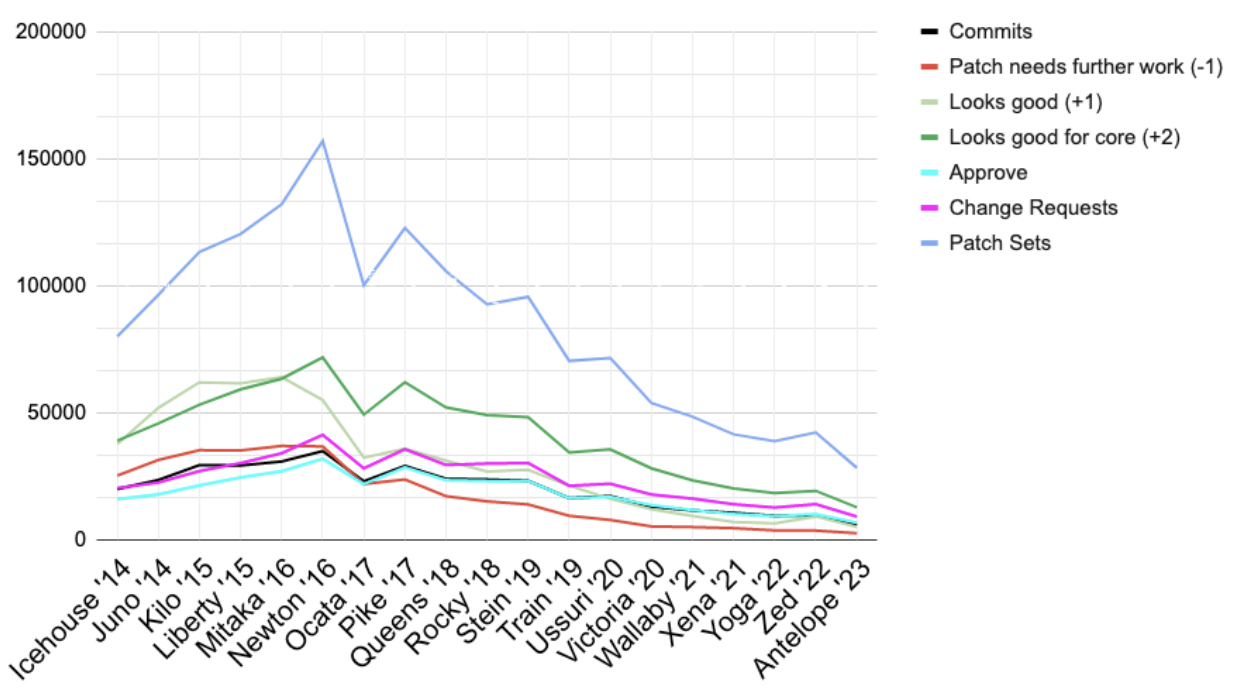
Figure 2 shows the activity in the OpenStack community. We can see that OpenStack development had been on the rise until the Newton release – in the second half of 2016. Starting 2017 – Ocata release – the development went over the hill and has been declining since.
The number of new lines of code has a similar trend, as seen in Figure 3.
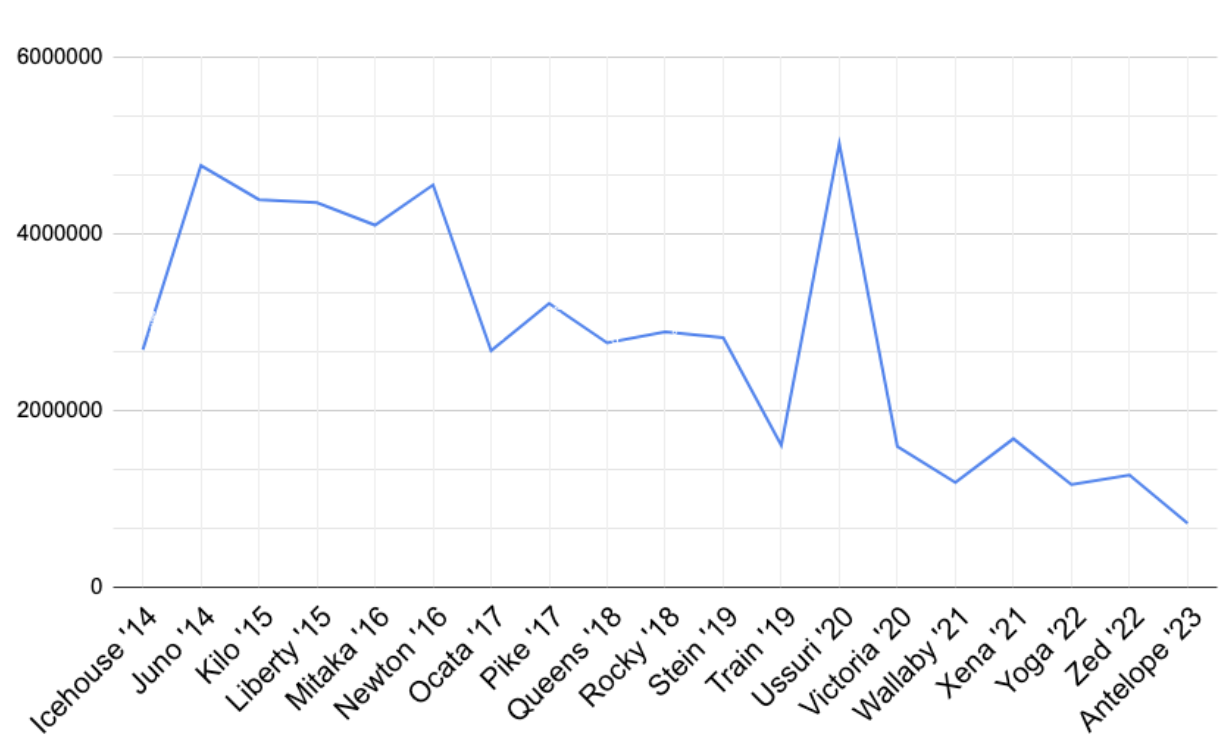
We can see a significant decrease in the number of lines of new code between the end of 2016 and 2020 when we had a new peak, however, the downtrend continues and has been declining since.
That of course correlates with the number of contributors per release, which can be seen in Figure 4.
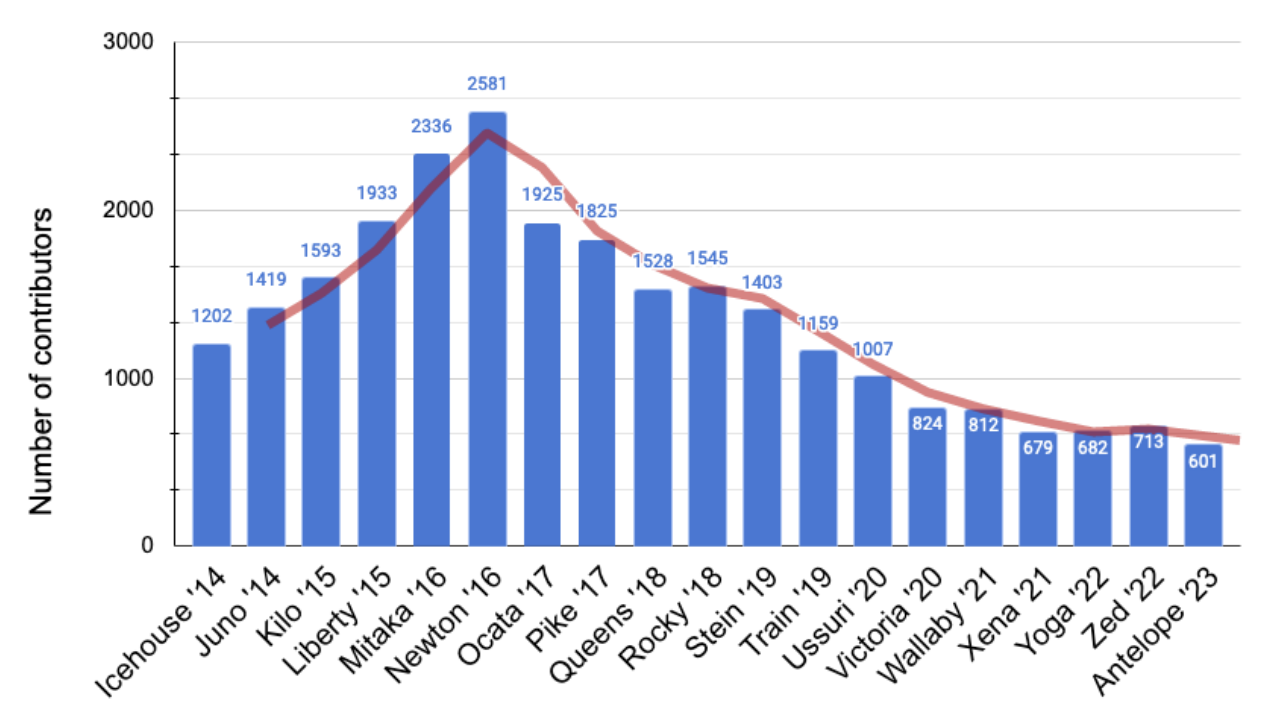
The decline in the number of contributors started with Ocata release in 2017 and has been practically on the decline since.
While the activity in the community experiences a decline, as you’ve read above, the number of OpenStack deployments has the opposite effect – it’s rapidly increasing! Let’s take a look at the 2022 OpenStack User Survey Report.
“OpenStack deployments hit a new milestone in 2022, reaching 40 million compute cores in production, a 60% increase compared to 2021 and an impressive 166% increase since 2020. Deployments continue to vary in size, with the majority of deployments (56%) falling between 100 and 10,000 cores.” [5]
Forming of new guidelines
The push to form a new guideline worked like this. When a new feature was developed, tempest tests testing that feature were written. When we had a new feature together with the tempest tests testing it, the relevant tests (only api ones) were proposed to interop to become a part of one of the next guidelines. If a cloud passed all the tests in a guideline, the cloud was verified as an OpenStack deployment – “it talks like an OpenStack, it is one, thus is interoperable with other OpenStack clouds”.
Generally speaking, the push to add new tests to interop came from developing a new feature. However, as the development of OpenStack is on the decline, as shown above, this push isn’t coming anymore – we already have all the features we wanted. That’s proven by the fact that the number of OpenStack deployments is rapidly increasing while the development activity has the opposite direction.
Do we need a new interop process?
With the increasing number of OpenStack deployments, it’s safe to say that also the variety of configurations is on the rise. More deployments equals more different use-cases which results in many different configurations of OpenStack. From that, we can safely assume that finding the set of tests that would pass on all deployments out there is problematic (e.g. some OpenStack functionalities are contradictory). Therefore maintaining a single guideline that should guarantee interoperability is unsustainable.
That, however, conflicts with the current interop process which worked during OpenStack development but doesn’t work now with all the different cloud configurations. That means that the clouds may either:
- Not pass a guideline, which would mean that the cloud isn’t an OpenStack cloud, which is not true.
- Pass a guideline, however, the small (as it has to pass on all the different configurations) set of tests can’t realistically say that two clouds passing the tests are interoperable as those may have functionalities that are not tested by the tests and there is even a chance that the functionalities are complementary which could potentially result in a situation that those two clouds can’t fully communicate with each other thus are not interoperable per the very definition of interoperability.
This brings us to the following question: what should interoperability mean for OpenStack deployments now? Well, it’s the same as before. We want to be able to tell whether two clouds can communicate with each other. However, due to all the different cloud configurations with different functionalities (even complementary ones), we can’t look at it binary – two clouds are or are not interoperable.
We should introduce a certain fuzzy logic into the process. That would allow us to put the interoperability between two clouds on a scale and get a number telling us how well those two clouds can communicate with each other.
The fuzzy logic would allow us to keep up with the increasing number of cloud configurations, scale the interop testing and provide users a way to compare cloud solutions and f.e. make their migration easier. Users have different expectations and use cases to solve, thus their required interoperability levels will vary while the interoperability still means the same.










