)
OpenInfra Live is a weekly hour-long interactive show streaming to the OpenInfra YouTube channel every Thursday at 14:00 UTC (9:00 AM CT). Episodes feature more OpenInfra release updates, user stories, community meetings, and more open infrastructure stories.
When we talk about Large Scale, it usually refers to scaling out to hundreds of thousands of commodity nodes. But there is another dimension to Large Scale OpenStack: using OpenStack to build supercomputers to use in research and HPC. In this episode, operators of OpenStack supercomputers and HPC centers will discuss the unique challenges this use case brings.
Enjoyed this week’s episode and want to hear more about OpenInfra Live? Let us know what other topics or conversations you want to hear from the OpenInfra community this year, and help us to program OpenInfra Live! If you are running OpenStack at scale or helping your customers overcome the challenges discussed in this episode, join the OpenInfra Foundation to help guide OpenStack software development and to support the global community.
The State of Research Computing, Scientific Computing, and Supercomputing
Stig Telfer, CTO of StackHPC, kicked off the episode by setting the stage around how scientific computing has been on an incredible journey and it’s a journey from conventional scientific computing, infrastructure management to a way cloud has transformed this space.
“In modern computing environments when we are looking to create innovation, we quite often need to start at the software level, so we need this idea of being self-service and this is another example of where cloud comes in,” he said. “This is an example of how OpenStack is transforming the scientific computing landscape. If you look at things like GPUs for example, they could be used in so many different compute platforms, containerization or in high performance computing and for modeling.”
Taking a step back from the broad landscape of research computing, Telfer talked about the pinnacle where there is a niche domain of supercomputing. In this environment, there are systems that exist among the biggest and most powerful supercomputers today that are running OpenStack—several of which joined the episode to talk about their use case and OpenStack implementation. He prefaced the discussion by explaining that the way that the supercomputers work breaks every assumption in how we usually think about cloud working.
CSCS Use Case
Sadaf Alam, CTO of Swiss National Supercomputing Center (CSCS) which provides supercomputing and large scale data processing to Swiss research, academic communities and more, introduced how CSCS used OpenStack to leverage high performing computing technologies.
“We have an OpenStack system running that provides infrastructure as a service for our customers,” she said. “It provides valuable service, resources and type of privilege and access controls users can’t get on other high-end systems.”
Center for High Performance Computing Use Case
Next up we have Happy Sithole, Centre for High Performance Computing (CHPC) manager of the National Integrated Cyber Infrastructure System (NICIS). CHPC is one of the three pillars of the NICIS. It provides massive parallel processing capabilities and services to researchers in industry and academia. He explained CHPC’s roadmap which is fully OpenStack on HPC system and the goal of operating one large infrastructure based on OpenStack bare metal that meets the requirements for all users.

The role of OpenStack is even more crucial to the COVID-19 situation in South Africa. Sithole emphasized how OpenStack helps them to map out connectivity across the country, such as helping the government to understand students’ activities at the universities and at home. “After three days of lockdown when we were provisioning our OpenStack, we are hard at work to save lives in our country,” Sithole said.
“OpenStack provides a different offering for users of the data center,” Sithole explained in this article. “This implementation is a step in the right direction to revolutionize our data center as a converged environment. We see this as a continuum between compute-intensive and data-intensive computing. It allows us to easily support both HPC research and general purpose cloud computing in the same infrastructure.”

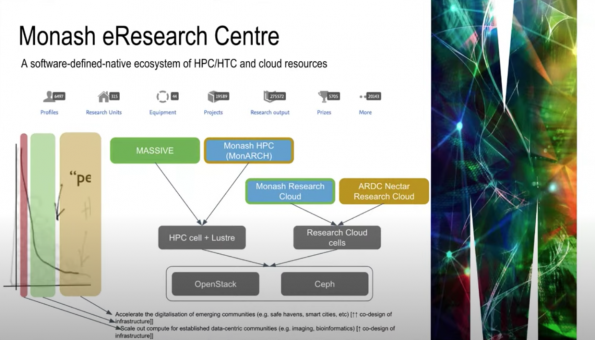
Monash e-Research Centre
Steve Quenette, deputy director of e-Research Centre at Monash University, one of the largest universities in Australia, explained the challenges they face with traditional HPC from a supercomputing perspective.
The Monash e-Research Centre, a software-definied-native ecosystem of HPC/HTC and cloud resources, is based on OpenStack and Ceph. They power all of their HPC and their cloud presented usage.
Quenette also described how Monash University leverages crowdsourcing to find vulnerabilities as well as crowdsourcing to help them fix the vulnerabilities to improve security visibility and continuous assurance. On the other hand, they also partnered with NVIDIA and ARDC to explore the offloading of security in collaborating research applications.
NASA Center for Climate Simulation
Jonathan Mills, cloud computing technical team lead at NASA Center For Climate Simulation, explained how they use their large OpenStack cloud with 200+ nodes to do massive climate modeling that runs on their supercomputers.
Mill’s team has been working on building Explore since 2019 which is an upgrade on two previous OpenStack clusters. One was focused on Infrastructure-as-a-Service (IaaS), and the other one was focused on Platform-as-a-Service (PaaS). Explore will host both of them. Discover is their traditional bare-metal HPC machine, and anything that isn’t a good fit for Discover can run in Explore. In the images below, you will be able to see how NASA’s private cloud and HPC coexist together and how OpenStack supports NASA science in various ways.


Live Q&A
What is so difficult about peak systems?
How is OpenStack playing a role in the Square Kilometer Array (SKA)?
What are some data challenges when combining a supercomputer environment with an OpenStack system?
How can OpenStack help to generate innovative solutions in data analysis?
What other infrastructure tools do you use?
What can be added to OpenStack to better support your operations?
What is going to be the effect of technologies into the software-defined supercomputer environment?
Next Episode on #OpenInfraLive
Interested in learning more or improving your open source development skills? Looking to learn more about OpenStack and Kubernetes administration and prep for the Certified OpenStack Administrator or Certified Kubernetes Administrator exams? Join us as OpenInfra organizations discuss their training programs and how they can accelerate your open source career.
Tune in on Thursday, September 2 at 1400 UTC (9:00 AM CT) to watch this #OpenInfraLive episode: Open Source Training Opportunities.
You can watch this episode live on YouTube, LinkedIn and Facebook. The recording of OpenInfra Live will be posted on OpenStack WeChat after each live stream!
Like the show? Join the community!
Catch up on the previous OpenInfra Live episodes on the OpenInfra Foundation YouTube channel, and subscribe for the Foundation email communication to hear more OpenInfra updates!









