)
OpenStack is a cloud computing platform that is designed to be highly scalable. However, even though OpenStack is designed to be scalable, there are a few potential bottlenecks that can occur in large deployments. These bottlenecks typically involve the performance and throughput of RabbitMQ and MariaDB clusters.
RabbitMQ is a message broker that is used to decouple different components of OpenStack. MariaDB is a database that is used to store data for OpenStack. If these two components are not performing well, it can have a negative impact on the performance of the entire OpenStack deployment.
There are a number of different methodologies that can be used to improve the performance of RabbitMQ and MariaDB clusters. These methodologies include scaling up the clusters, using a different message broker or database, or optimizing the configuration of the clusters.
In this article, we will discuss the potential bottlenecks that can occur in large OpenStack deployments and ways to scale up deployments to improve the performance of RabbitMQ and MariaDB clusters.
NOTE: Examples provided in this article were made on OpenStack 2023.1 (Antelope). It is possible to achieve the same flows in earlier releases, but some extra steps or slightly different configurations might be required.
Most Common Deployment
But before talking about ways on how to improve things, let’s quickly describe our “starting point”, to understand what we’re dealing with at the starting point.
The most common OpenStack-Ansible deployment design is three control nodes, each one is running all OpenStack API services along with supporting infrastructure, like MariaDB and RabbitMQ clusters. This is a good starting point for small to medium-sized deployments. However, as the deployment grows, you may start to experience performance problems. Typically communication between services and MySQL/RabbitMQ looks like this:
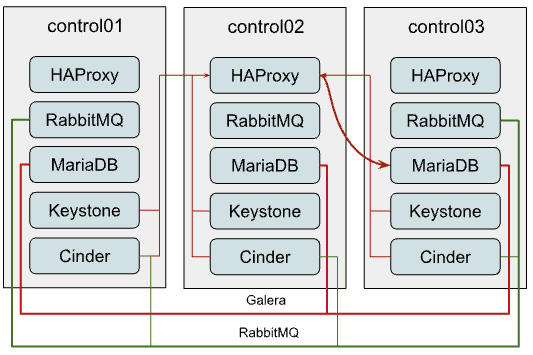
MariaDB
As you might see on the diagram, all connections to MariaDB come through the HAProxy which has Internal Virtual IP (VIP). OpenStack-Ansible does configure the Galera cluster for MariaDB, which is a multi-master replication system. Although you can issue any request to any member of the cluster, all write requests will be passed to the current “primary” instance creating more internal traffic and raising the amount of work each instance should do. So it is recommended to pass write requests only to the “primary” instance.
However HAProxy is not capable of balancing MySQL queries at an application level (L7 of OSI model), to separate read and write requests, so we have to balance TCP streams (L3) and pass all traffic without any separation to the current “primary” node in the Galera cluster, which creates a potential bottleneck.
RabbitMQ
RabbitMQ is clustered differently. We supply IP addresses of all cluster members to clients and it’s up to the client to decide which backend it will use for interaction. Only RabbitMQ management UI is balanced through haproxy, so the connection of clients to queues does not depend on HAProxy in any way.
Though usage of HA queues and even quorum queues makes all messages and queues to be mirrored to all or several cluster members. While quorum queues show way better performance, they still suffer from clustering traffic which still becomes a problem at a certain scale.
Option 1: Independent clusters per service
With this approach, you might provide the most loaded services, like Nova or Neutron, their standalone MariaDB and RabbitMQ clusters. These new clusters might reside on a separate hardware.
In the example below we assume that only Neutron is being reconfigured to use the new standalone cluster, while other services remain sharing the already existing one.
So Neutron connectivity will look like this:
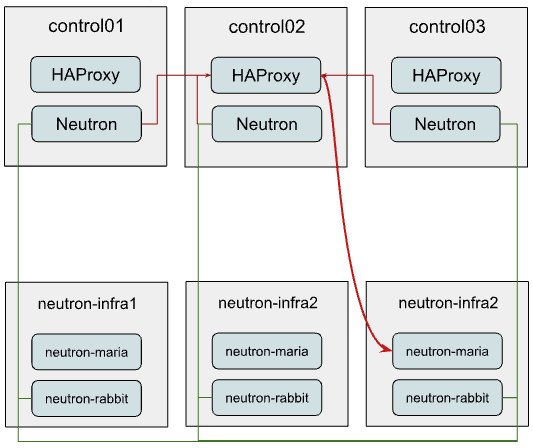
As you might have noticed, we still consume the same HAProxy instance for MySQL balancing to the new infra cluster.
Next, we will describe how to configure such a stack and execute the service transition to this new layout.
Setup of new MariaDB and RabbitMQ clusters
To configure such a layout and migrate Neutron using it with OpenStack-Ansible you need to follow these steps:
NOTE: You can reference the following documentation for a deeper understanding of how env.d and conf.d files should be constructed: https://docs.openstack.org/openstack-ansible/latest/reference/inventory/understanding-inventory.html
- Define new groups for RabbitMQ and MariaDB. For that, you can create files with the following content:
/etc/openstack_deploy/env.d/galera-neutron.yml:
# env.d file are more clear if you read them bottom-up # At component skeleton you map component to ansible groups component_skel: # Component itself is an ansible group as well neutron_galera: # You tell in which ansible groups component will appear belongs_to: - neutron_galera_all - galera_all # At container skeleton you link components to physical layer container_skel: neutron_galera_container: # Here you define on which physical hosts container will reside belongs_to: - neutron-database_containers # Here you define which components will reside on container contains: - neutron_galera # At physical skeleton level you map containers to hosts physical_skel: # Here you tell to which global group containers will be added # from the host in question. # Please note, that <name>_hosts and <name>_containers are # interconnected, and <name> can not contain underscores. neutron-database_containers: belongs_to: - all_containers # You define `<name>_hosts` in your openstack_user_config or conf.d # files to tell on which physical hosts containers should be spawned neutron-database_hosts: belongs_to: - hosts
/etc/openstack_deploy/env.d/rabbit-neutron.yml:
# On the component level we are creating group `neutron_rabbitmq` # that is also part of `rabbitmq_all` and `neutron_rabbitmq_all` component_skel: neutron_rabbitmq: belongs_to: - rabbitmq_all - neutron_rabbitmq_all # On the container level we tell to create neutron_rabbitmq on # neutron-mq_hosts container_skel: neutron_rabbit_mq_container: belongs_to: - neutron-mq_containers contains: - neutron_rabbitmq # We define the physical level as a base level which can be consumed # by container and component skeleton. physical_skel: neutron-mq_containers: belongs_to: - all_containers neutron-mq_hosts: belongs_to: - hosts
Map your new neutron-infra hosts to these new groups. To add to your openstack_user_config.yml the following content:
neutron-mq_hosts: &neutron_infra neutron-infra1: ip: 172.29.236.200 neutron-infra2: ip: 172.29.236.201 neutron-infra3: ip: 172.29.236.202 neutron-database_hosts: *neutron_infra
- Define some specific configurations for newly created groups and balance them:
- MariaDB
- In file /etc/openstack_deploy/group_vars/neutron_galera.yml:
galera_cluster_members: "{{ groups['neutron_galera'] }}" galera_cluster_name: neutron_galera_cluster galera_root_password: mysecret
In file /etc/openstack_deploy/group_vars/galera.yml:
galera_cluster_members: "{{ groups['galera'] }}"
- Move `galera_root_password` from /etc/openstack_deploy/user_secrets.yml to /etc/openstack_deploy/group_vars/galera.yml
- RabbitMQ
In file /etc/openstack_deploy/group_vars/neutron_rabbitmq.yml:
rabbitmq_host_group: neutron_rabbitmq rabbitmq_cluster_name: neutron_cluster
In file /etc/openstack_deploy/group_vars/rabbitmq.yml
rabbitmq_host_group: rabbitmq
- HAProxy
In /etc/openstack_deploy/user_variables.yml define extra service for MariaDB:
haproxy_extra_services: - haproxy_service_name: galera_neutron haproxy_backend_nodes: "{{ (groups['neutron_galera'] | default([]))[:1] }}" haproxy_backup_nodes: "{{ (groups['neutron_galera'] | default([]))[1:] }}" haproxy_bind: "{{ [haproxy_bind_internal_lb_vip_address | default(internal_lb_vip_address)] }}" haproxy_port: 3307 haproxy_backend_port: 3306 haproxy_check_port: 9200 haproxy_balance_type: tcp haproxy_stick_table_enabled: False haproxy_timeout_client: 5000s haproxy_timeout_server: 5000s haproxy_backend_options: - "httpchk HEAD / HTTP/1.0\\r\\nUser-agent:\\ osa-haproxy-healthcheck" haproxy_backend_server_options: - "send-proxy-v2" haproxy_allowlist_networks: "{{ haproxy_galera_allowlist_networks }}" haproxy_service_enabled: "{{ groups['neutron_galera'] is defined and groups['neutron_galera'] | length > 0 }}" haproxy_galera_service_overrides: haproxy_backend_nodes: "{{ groups['galera'][:1] }}" haproxy_backup_nodes: "{{ groups['galera'][1:] }}"
- Prepare new infra hosts and create containers on them. For that, run the command:
openstack-ansible playbooks/setup-hosts.yml --limit neutron-mq_hosts,neutron-database_hosts,neutron_rabbitmq,neutron_galera - Deploy clusters:
- MariaDB:
openstack-ansible playbooks/galera-install.yml --limit neutron_galera - RabbitMQ:
openstack-ansible playbooks/rabbitmq-install.yml --limit neutron_rabbitmq
- MariaDB:
Migrating the service to use new clusters
While it’s relatively easy to start using the new RabbitMQ cluster for the service, migration of the database is slightly tricky and will include some downtime.
First, we need to tell Neutron that from now on, the MySQL database for the service is listening on a different port. So you should add the following override to your user_variables.yml:
neutron_galera_port: 3307
Now let’s prepare the destination database: create the database itself along with required users and provide them permissions to interact with the database. For that, we will run the neutron role with a common-db tag and limit execution to the neutron_server group only. You can use the following command for that:
openstack-ansible playbooks/os-neutron-install.yml --limit neutron_server --tags common-db
Once we have a database prepared, we need to disable HAProxy backends that proxy traffic to the API of the service in order to prevent any user or service actions with it.
For that, we use a small custom playbook. Let’s name it haproxy_backends.yml:
- hosts: haproxy_all tasks: - name: Manage backends community.general.haproxy: socket: /run/haproxy.stat backend: "{{ backend_group }}-back" drain: "{{ haproxy_drain | default(False) }}" host: "{{ item }}" state: "{{ haproxy_state | default('disabled') }}" shutdown_sessions: "{{ haproxy_shutdown_sessions | default(False) | bool }}" wait: "{{ haproxy_wait | default(False) | bool }}" wait_interval: "{{ haproxy_wait_interval | default(5) }}" wait_retries: "{{ haproxy_wait_retries | default(24) }}" with_items: "{{ groups[backend_group] }}"
We run it as follows:
openstack-ansible haproxy_backends.yml -e backend_group=neutron_server
No, we can stop the API service for Neutron:
ansible -m service -a "state=stopped name=neutron-server" neutron_server
And run a backup/restore of the MySQL database for the service. For this purpose, we will use another small playbook, that we name as mysql_backup_restore.yml with the following content:
- hosts: "{{ groups['galera'][0] }}" vars: _db: "{{ neutron_galera_database | default('neutron') }}" tasks: - name: Dump the db shell: "mysqldump --single-transaction {{ _db }} > /tmp/{{ _db }}" - name: Fetch the backup fetch: src: "/tmp/{{ _db }}" dest: "/tmp/db-backup/" flat: yes - hosts: "{{ groups['neutron_galera'][0] }}" vars: _db: "{{ neutron_galera_database | default('neutron') }}" tasks: - name: Copy backups to destination copy: src: "/tmp/db-backup/" dest: "/tmp/db-backup/" - name: Restore the DB backup shell: "mysql {{ _db }} < /tmp/db-backup/{{ _db }}"
Now let’s run the playbook we’ve just created:
openstack-ansible mysql_backup_restore.yml
NOTE: The playbook above is not idempotent as it will override database content on the destination hosts.
Once the database content is in place, we can now re-configure the service using the playbook.
It will not only tell Neutron to use the new database but also will switch it to using the new RabbitMQ cluster as well and re-enable the service in HAProxy.
For that to happen we should run the following command:
openstack-ansible playbooks/os-neutron-install.yml --tags neutron-config,common-mq
After the playbook has finished, neutron services will be started and configured to use new clusters.
- Scaling OpenStack-Ansible Deployment: RabbitMQ and MariaDB – Option Three - August 27, 2023
- Scaling OpenStack-Ansible Deployment: RabbitMQ and MariaDB – Option Two - August 26, 2023
- Scaling OpenStack-Ansible Deployment: RabbitMQ and MariaDB – Option One - August 25, 2023







