)
For people who have attended the Open Infrastructure Summits in recent years, you have probably heard of the first winner of the Superuser Awards, CERN. CERN is the European Organization for Nuclear Research. It has a laboratory that is located at the border between France and Switzerland, and the main mission of CERN is to uncover what the universe is made of and how it works.
For a few years, all physical servers deployed in the CERN IT data centers have been provisioned as part of the OpenStack private cloud offering, leveraging Nova and Ironic. What started with a few test nodes has now grown to more than 5,000 physical machines, with the aim to move to around 10,000 nodes.
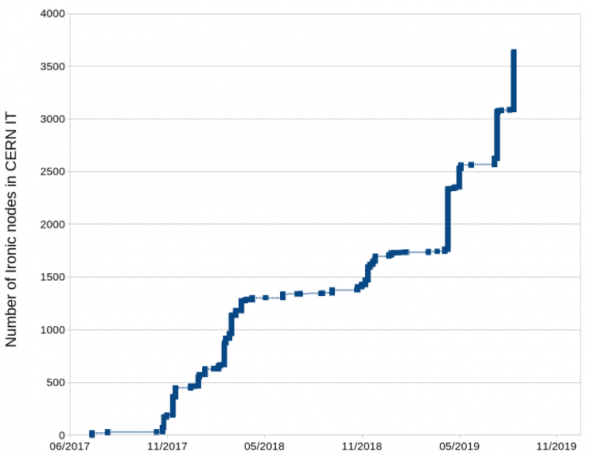
CERN’s Nova and Ironic Deployment
CERN and CERN IT rely heavily on OpenStack, and we have deployed OpenStack in production since 2013 with around 8,500 compute nodes with 300k cores and 35k instances in around 80 cells. In addition, we deploy three regions mainly for scalability and to ease the rollout of the new features.
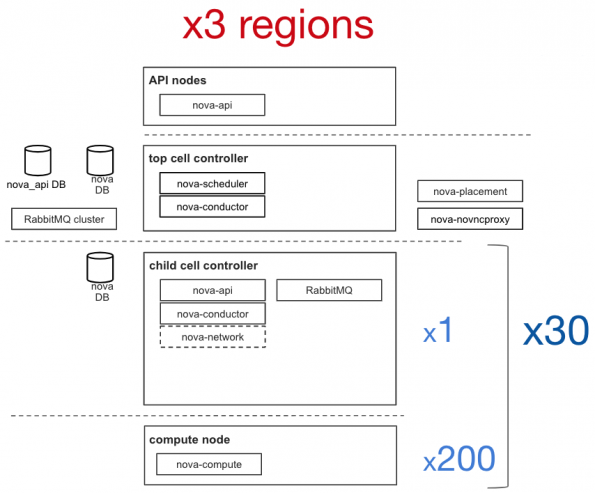
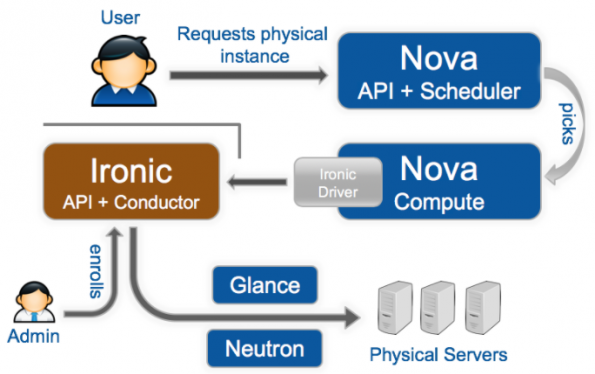
Issues and Solutions when Scaling Bare Metal with Nova and Ironic
When we scaled our bare metal deployment with Nova and Ironic to several thousand nodes, we encountered three main issues so far:
- Controller Crashes
- API Responsiveness
- Resource Discovery
Scaling Issue 1: Controller Crashes
The CERN Cloud Infrastructure Team uses the iscsi deploy interface for Ironic. It means that a node upon deployment is exporting an iscsi device to the controller, and the controller is then dumping the image downloaded from Glance onto it. (Note that this deploy interface will be deprecated in the future, so direct deploy interface should be used instead.)
For deployment, since the images are tunneled through the controller, many parallel deployments will drive the conductor into out-of-memory (OOM) situations. In consequence, the controller would crash and leave the nodes in an error state.
Solutions
To address this issue we horizontally scaled the controllers and introduced the “wing” controllers to have more controllers to handle the requests. Another solution would be to use a scalable deploy interface, such as direct or ansible which makes the node download the image directly.
Scaling Issue 2: API Responsiveness
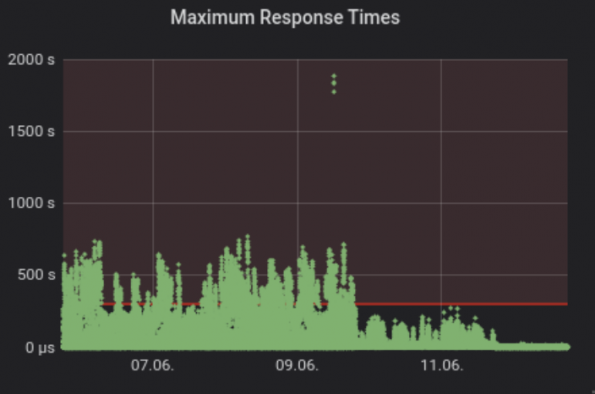
When scaling up the infrastructure, we noticed that all requests involving the database were slow. Looking at the request logs, we realized that the inspector as the other component running on the controller gets a list of all nodes to clean up its database every 60 seconds. In addition, we had disabled pagination when we reached 1,000 nodes, which means that every request that went to the API assembled all the nodes in one giant request and tried to give that back to the requester.
Solutions
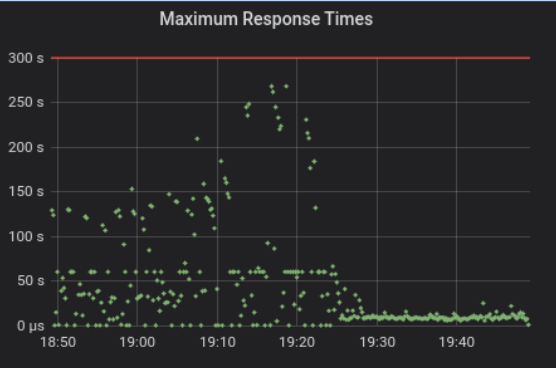
To solve this issue, we re-enabled pagination and changed the sync interval from 60 seconds to one hour. You can see how this solution affected the response time from the graph below. For a more scalable solution, we introduced “Inspector Leader Election”, which we developed together with upstream and deployed now in production. Inspector Leader Election will be available in the Victoria release, and you can see more details about how it works here.
Scaling Issue 3: Resource Discovery
Another issue that we faced when increasing the number of physical nodes managed by Ironic is the time that the Resource Tracker (RT), which runs in each nova-compute, takes to report all the available resources to Placement. From the graph below, you can see the original OpenStack Nova and Ironic setup for the dedicated bare metal cell at CERN.
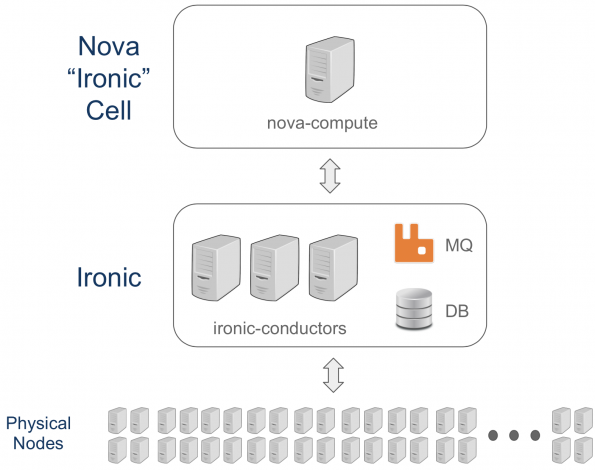
There is a dedicated Nova cell for Ironic which is the standard way that we partition and manage the infrastructure. In the dedicated Nova cell, we only have the cell control plane, nova-conductor, RabbitMQ, and nova-compute. This single nova-compute is responsible for all the communication between Nova and Ironic using the Ironic API. It is possible to run several nova-computes in parallel based on a hash ring to manage the nodes, but when we were testing this functionality, several issues were observed.
Since there is only one nova-compute that interacts with Ironic and the RT needs to report all the Ironic resources, the RT cycle takes a long time when the number of resources is increased in Ironic. In fact, it took more than three hours to complete our deployment with about 5,000 nodes. During the RT cycle, all the users’ actions are queued until all the resources are updated. This created a bad user experience with the new resources creation taking a few hours.
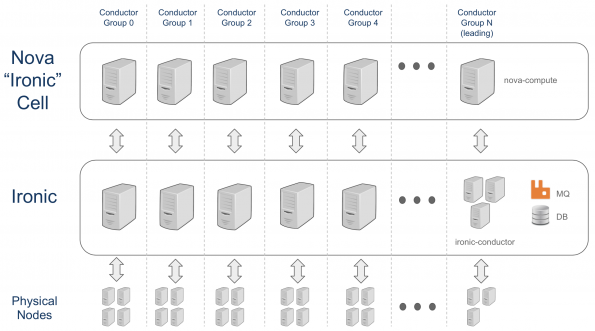
Conductor Groups
In order to have failure domains in Ironic and to allow to split the infrastructure, a new feature was introduced in the Stein release of Ironic and Nova. It’s called “conductor groups”. A conductor group is an association between a set of physical nodes and a set of (one or more) Ironic conductors which manage these physical nodes. This association reduces the number of nodes a conductor is looking after, which is key in scaling the deployment.
Conductor Groups Configuration
The conductor group an Ironic conductor is taking care of is configured in Ironic’s configuration file “ironic.conf” on each Ironic conductor:
[conductor]
conductor_group = MY_CONDUCTOR_GROUPNext, each Ironic resource needs to be mapped to the conductor group that is selected, and this can be done in the Ironic API.
openstack baremetal node set --conductor-group "MY_CONDUCTOR_GROUP"
<node_uuid>Finally, each group of nova-compute nodes needs to be configured to manage only a conductor group. This is done in Nova’s configuration file “nova.conf” for each “nova-compute” node:
[ironic]
partition_key = MY_CONDUCTOR_GROUP
peer_list = LIST_OF_HOSTNAMESNow, there is one nova-compute per conductor group, and you can see how the deployment looks like in the graph below.
The Transition Steps
How did we deploy the conductor groups? The transition steps below are summarized from a CERN Tech Blog, Scaling Ironic with Conductor Groups.
- Nova-compute and Ironic services stopped since the databases will be manually updated
- Updated the Ironic and Nova configuration files with the conductor groups’ names
- Updated Ironic “nodes” tables to map conductor groups to nodes
- Updated Nova “compute_nodes” and “instances” tables to set the new nova-compute dedicated to the conductor groups
- Finally, start again all the services
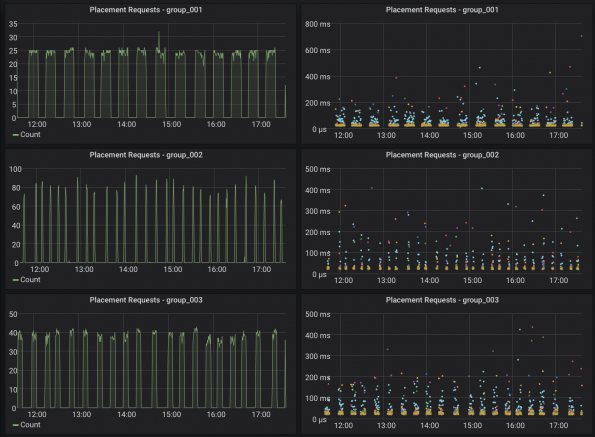
Impact on the Resource Tacker (RT) Cycle Time
In the graph below, you can see the number of Placement requests per conductor group. As a result, the RT cycle time now only takes about 15 minutes to complete instead of three hours previously since it’s now divided through the number of conductor groups.
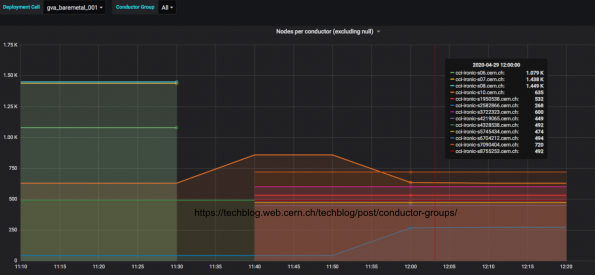
Number of Resources Per Conductor Group
How did we decide the number of resources per conductor groups? The RT cycle time increases linearly with the number of resources. The compromise between management and RT cycle time is around 500 nodes per conductor group in our deployment. The deployment scales horizontally as we add conductor groups
Conclusion and Outlook
Scaling infrastructure is a constant challenge! By introducing conductor groups, the CERN Cloud Infrastructure Team was able to split this locking and reduce the effective lock time from three hours to 15 minutes (and even shorter in the “leading” group)
Although we have addressed various issues, some issues are still open and new ones will arise. Good monitoring is key to see and understand issues.
Get Involved
This article is a summary of the Open Infrastructure Summit session, Scaling Bare Metal Provisioning with Nova and Ironic at CERN, and the CERN Tech Blog, Scaling Ironic with Conductor Groups.
Watch more Summit session videos like this on the Open Infrastructure Foundation YouTube channel. Don’t forget to join the global Open Infrastructure community, and share your own personal open source stories using the hashtag, #WeAreOpenInfra, on Twitter and Facebook.










