)
Background
This article is written by the Infrastructure and Cloud Service (ICS) Department, affiliated with the Internal IT of Lenovo Group.
With the rise of users’ requirements upon continuity and data reliability, ICS successfully set up an OpenStack-based private cloud using an active-active redundancy model to provide 100% availability to applications in 2020, a year stormed by Covid-19. This article will discuss five layers in detail from Datacenter, to Network, Storage, Computing and Service, along with infrastructure construction and application transformation. Furthermore, we will talk about how to build a private cloud of which RTO (Recovery Time Objective) ≈0 and RPO (Recovery Point Objective) = 0.
Intra-City Active-Active Deployment
The very first step to build an active-active cloud is the proper DC siting, which is the carrier of cloud computing. According to many existing sources, the distance between two intra-city sites should be within 100KM to fulfill the three-DC-in-two-city architecture. This solution means that two data centers are used as the production DC and disaster recovery is managed in a separate data center. Lenovo private cloud needs to realize real-time replication between two DCs to achieve the real Active-Active, even though it means that it would sacrifice performance to a certain extent. ICS selected two data centers which are located in two districts of Beijing with a linear distance of 25KM, and the distance of dual bare fibers is 55km. The distance of this physical line also forms the basis for the low latency of real-time data synchronization.

The key point of this solution is the communication between the two DCs. Real-time data replication has strict requirements not only on latency but also on bandwidth and reliability. ICS built dual active bare fibers which are the backup of each other in case of any accidental hardware damage. It also implemented Dense Wavelength Division Multiplexing (DWDM) technology to improve bandwidth and the utilization of bare fibers. This scheme results in very substantial performance: the bandwidth between the two DCs reaches 160GBps, and the RTT is less than 0.9ms according to our actual testing result at the virtualization layer. Storage system data and network data are running on the light waves of different wavelengths, to avoid the bandwidth pre-emption between storage and network.
Active-Active at Network Layer
ICS AA Cloud realizes L2 network communication using Data Center Interconnect (DCI) technology at the network layer. The benefit of it is that the IP address will not change when the VM instance migration happens between two DCs so as to further reduce service disruption scenarios caused by the infrastructure layer.
All devices work as an active-active mode within a single DC (stateless), like routers, Spine-Leaf switches, and load balancing servers. The cost of network disruption is negligible in the case of one single point of failure. Uniquely among those, the hardware firewall works in the Active-Standby mode case they always keep the session, which is stateful.
Meanwhile, the internet of two DCs adopts BGP multi-line technology and they are independent of each other. It normally implements two ways to cope with DC-level failure. The first is to use a load balancer, it will judge whether the link is available if failure happens at any site, then the traffic of the unavailable site will be scheduled to the other one. The second way is router convergence, which uses manual operation to converge the traffic of a faulted site to the other one during the early days after program launch. It will gradually become an automated process after we have matured failure rehearsal.
Active-Active at Storage Layer
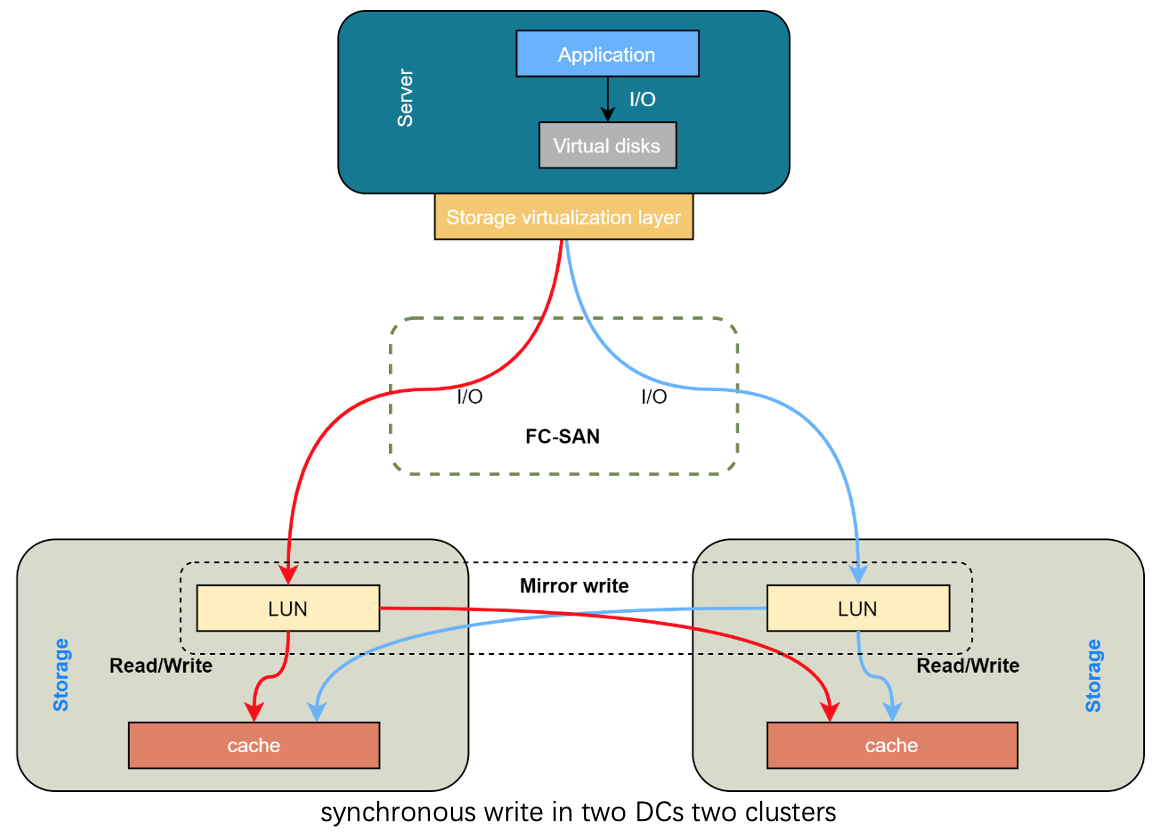
At the storage hardware layer, ICS applies DE series storage from Lenovo NetApp to build an FC-SAN all-flash cluster, and the capacity and specification are the same for both centers. Storage Visualization Engine is used above the all-flash storage, to dock with OpenStack Cinder.
As previously mentioned, our AA cloud design aimed to achieve synchronous replication at the storage layer. What makes it different from asynchronous replication is that IO could only be regarded as successful when data from both ends is written to disk or to the cache layer. This method could result in an IOPS performance issue. Nevertheless, we adopt the method of performance and high availability support from the data link layer and network layer, which could reduce the impact to the maximum extent.
As we all know, the reliability of the storage system has a huge impact on the overall availability of the system, especially in the cloud environment. We can see from the news that large-scale outages are caused by storage system failures. ICS adopts the storage solution with synchronous writing to make sure the RPO=0. Meanwhile, read operation runs at the local site so as to improve performance.
The other feature of this storage solution is that the OpenStack-instance-oriented LUN (Logical Unit Number) ID will not change while the other site is unavailable. The operation team could migrate the computing instances to the other side without the users noticing. Moreover, it will not affect the performance on the storage layer.
Active-Active at Computing Layer
It has been over ten years since the OpenStack project was born. 23 in total major versions have been released until the beginning of the year 2021 (the current version is Wallaby). It covers a wide range from the network to virtualization, operating system, storage, etc. A lot of best practice examples used in production can be referred to.
ICS set up the private cloud based on OpenStack, and ThinkSystem SR series high-performance servers manufactured by Lenovo. Different from the common use of OpenStack, these two datacenters can be regarded as one based on the features of L2 network communication, network and storage, to avoid the complexity of the cooperation between multiple OpenStack clusters and component sets.
Our scheme distributes control nodes into different racks and different hosts of two DCs. We use the way as the virtual machine mount the mirrored volume to deploy OpenStack service on the host cluster to cope with DC failure.
In terms of the deployment, ICS uses Kolla container to deploy OpenStack services. There is no dependency between service requests, and they are completely independent in OpenStack stateless services, like nova-api, nova-scheduler, glance-api, etc. For those services, it adopts the redundant instance method of KeepAlive+HAProxy to realize multiple active-active. For stateful service, it adopts Galera Cluster and RabbitMQ original cluster method to achieve high availability.
Computing instance active-active is mirroring image like VMware Fault Tolerance in the strict sense. Simply speaking, this solution can be achieved through real-time or near real-time instruction duplication to make two instances in the same state. The shadow instance will take control once any fault tolerance happens. The benefit of this approach is the realization of 0 outages, 0 data loss, elimination of the complexity of the traditional hardware/software cluster scheme, but it results in computing resource cost multiplying. ICS plans to access fault tolerance instance in the next phase based on COLO(COarse-grained LOck-stepping Virtual Machines for Non-stop Service) component. For now, we made a lot of development in the OpenStack community and in monitoring data, to ensure the availability of virtual machine clusters.
The realization of the community version of Server Group can only add newly applied servers into the existing group, but the existing instance can’t add newly applied servers as this could break the scheduling rule. ICS developed high availability server group engine on its own, to make any VMs capable of joining existing or newly built server groups. As for the existing instance scheduled by nova-scheduler, users can set the enable/disable to satisfy the affinity rule or do inspections during the window. It also realizes the high availability scheduling in multiple granularities from hosts, racks, DCs, etc.
Moreover, ICS also-developed Auto-Failover engine, which can locate the failure point from multiple layers like network, storage, hosts, etc. If any failure was located, it will evacuate instances to the appointed failover available domains. For example, a computing node with 96 cores, 1.5T and oversubscription ratio of 2, only takes minutes from monitoring data analysis to fault position and the evacuation of the whole host node.
ICS uses machine learning to analyze the data from multiple layers like host power consumption, temperature, humidity, etc. This can previously do live migration of those going-to-fail hosts, to enter the AIOps era.
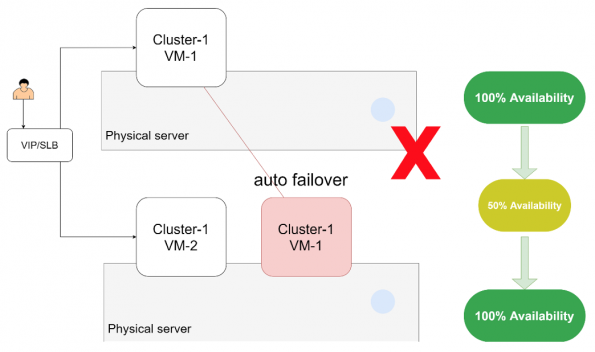
In general, it costs less to achieve active-active from the upper layer than that of the bottom layer. The output of upper-level solutions is more universal as many system failures result from code bugs and uncovered abnormal operations. Meanwhile, the method of high availability at the bottom layer will replicate the ‘failing instruction’ onto the ‘shadow instance’.
Active-Active at Service Layer
ICS has achieved active-active and high availability of link, network, storage and computing at the infrastructure level. Nevertheless, for the application developers, it is still hard to have best practices from the bottom to the top.
Taking the load balancing service as an instance, applications could be deployed at two DCs in the form of a distributed cluster. The cluster reuses the instance affinity rules mentioned in the last chapter. ICS deployed a multi-site global server load balancing service all around the world. It will automatically judge the healthiest, the least loaded point with the most optimized route. There is also a load balancing service deployed inside, to ensure higher bearing capacity.
Besides the load balancing service, ICS develops private cloud product and solution matrix combining the group function attributes. For example, users can apply a database cluster through self-service. It can provide intelligent scheduling of database instances according to affinity rules while all those clusters were deployed in the active-active private cloud environment. If users apply for MQ, it is capable of delivering many options like MQ tenant, independent cluster, federal, and no need to apply for computing instance deployment application cluster. Those service catalogs are quickly expanding to achieve a quick delivery of high availability applications.
The high availability design of infrastructure can also be applied at container platform which is deployed on physical machines or virtual machines. We can also achieve active-active stateful service combined with OpenStack Cinder. So far, this project has provided an end-to-to scheme of high availability clusters from infrastructure, to the private cloud, virtual machines, containers and applications.
Conclusion
In general, ICS has reached its initial target that builds an intra-city active-active private cloud based on OpenStack, from infrastructure design to upper software cluster delivery. The whole process of design and implementation is far more difficult than this article could describe in terms of technical and scheme details. The current trend is that companies need to embrace the service transformation including Lenovo. Lenovo embraces the trend of transformation from the technology level, like IoT, Serverless, AI, machine learning, meanwhile is willing to output solutions and products at the business level to help customers focus on delivering their own business and creating more value in ways that are more agile and cost-efficient.