)
At the OpenStack Summit in Paris, Tapjoy’s Head of Operations, Wes Jossey, chronicled the company’s journey with OpenStack. Jossey focused his session on the enduring impact that OpenStack has had on Tapjoy since they decided to go hybrid in June of 2014, yielding impressive capacity gains without increasing spend.
At a high level, Tapjoy is a global app-tech company focused on providing different techniques and tools for developers to power their mobile applications (whether it be monetization, analytics, user acquisition, and/or user retention). Think of them as an SDK in a library that people can use to power and monetize their apps. Currently serving over 450 million monthly users across 270,000+ apps worldwide, they have grown exponentially in a relatively short period of time.
The company was an early AWS adopter, and grew predominantly on the AWS platform. They have over 1,100 active AWS VMs daily, and that number only continues to grow. With active regions in Asia, Europe and North America, Tapjoy services over one trillion requests annually. This is 60% more than when Wes joined the company a little over two years ago.
Tapjoy’s tech philosophy
The company is very compute-driven (specifically, EC2 and Nova). They prefer to operate their own infrastructure, but don’t necessarily want to build it from scratch.
According to Jossey, “…we don’t want anything to be scary if it goes away. So, we always plan for nodes to terminate at any time — to always have redundancy and resiliency in the event that one of those nodes does terminate.”
They refer to this concept as “Zero Heart Attack Nodes”. This means that all nodes are ephemeral, data is always distributed, failure is always tolerated, and misbehaving instances are terminated quickly.
Primary services used
- SQS because it’s simple, inexpensive, and durable. In tandem, they’re building their own internal system that’s based on SQS but with no guarantees
- RDS to manage MYSQL instances. They don’t use MYSQL a ton, but RDS is simple, with no lock in
- Cloudwatch (in addition to Librato)
- ELB, for SSL termination only. Behind the scenes, they have their own personal load balancing layers so that the instances attached the the ELB are static
- Auto-scaling, tying it into different metrics to spin up and down their instances inside of Amazon. Their traffic fluctuates pretty dramatically over the course of the day (30% peak to valley), so they leverage auto-scaling to save money
- S3, where they store every single request throughout the entire history of Tapjoy.
“Use compute everywhere”
Tapjoy has used compute throughout their entire lifecycle. Each dev has access to either AWS or Tapjoy-1 (Tapjoy’s OpenStack deployment).
So, any developer, at any time, can set up a VM in either of their clouds and gain access to a large number of instances. This is great for R&D, for simulating changes, and for learning how applications will perform under certain workloads.
They rely heavily on the concept that compute is elastic and accessible. They also practice and prepare for failure, across the board. No surprises.
Going hybrid
Obviously, Tapjoy is no longer AWS-exclusive. The team decided that AWS was not a perpetual fit, and was not going to be cost-effective over the long term. So, they decided to pick a particular workload to take over and pour into Tapjoy-1.
As a next step, they sought a partner (spoiler alert: Metacloud) to maintain their OpenStack deployment — they didn’t want to start from ground zero to build their own, and lacked the core expertise to do so.
OpenStack timeline
It took Tapjoy just over a year to get OpenStack up and running, spanning from April 2013 to June 2014.
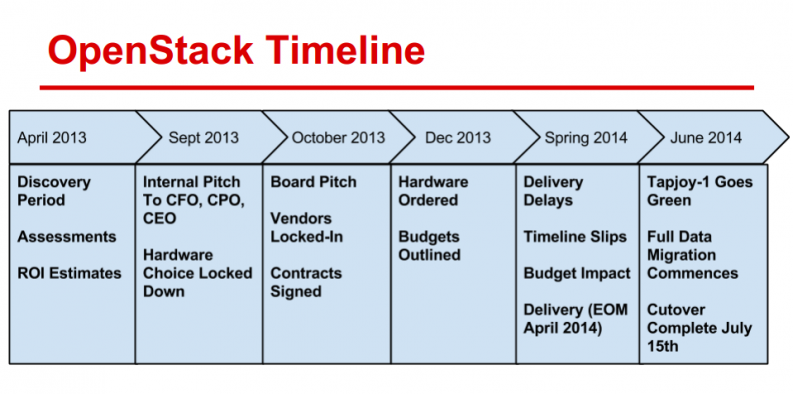
Vendors
They worked with a handful of excellent vendors throughout the implementation process to help with deployment, verify design, provision the network, and more. Among them were Metacloud, Equinix, Quanta, Cumulus, Level3, and Newegg.
Challenges
Hardware delays were a primary pain point throughout the process. They ate through budget, blew through contingency windows, and delayed subsequent purchases. Also, setting up the IP transit proved to be a surprisingly long process.
Furthermore, Tapjoy has no physical presence in DC. It’s good to be separated from a distance perspective, but also makes it tricky to get things done efficiently.
Lastly, there was a lot of skepticism within the organization. There were no prior success stories to point to, and getting buy-in was tough.
So, what did Tapjoy build?
In total, they built 348 all-purpose nodes intended to primarily serve Hadoop and HBase (and to also be recyclable if needed).

They also have 12 management nodes that are larger instances with more RAM, more SSD, and more network.

Same price, different outcome
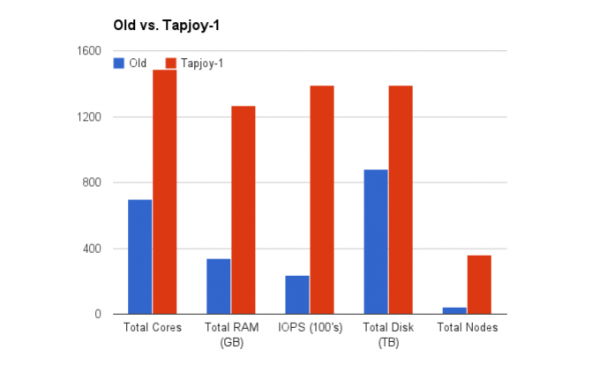
The blue line represents the old infrastructure (that was replaced), and the red line represents the new infrastructure in Tapjoy-1. In some cases, actual capacity gains increased 10X+.
Remarkably, they spent the exact same amount of money as was spent before — essentially trading monthly operating expenses for an upfront capital investment, which yielded massive infrastructure gains.
Planning for failure
Sound advice from Jossey: “You should plan for failure.”
The Tapjoy team tries to think of everything as ephemeral, so they don’t use CEPH or EBS.
In general, “…have hardware and software contingencies, run a backup link, use temporary caches in the event that something goes down. Always have a fall-back plan, no matter what.”
To learn more about Tapjoy’s OpenStack infrastructure, see Wes Jossey’s entire talk at the OpenStack Summit in Paris:
- Tales from the Trenches: The Good, the Bad, and the Ugly of OpenStack Operations - January 22, 2015
- Kilo Update: Zaqar - January 16, 2015
- OpenStack Documentation & Review Cycle Management – Kilo Update - December 12, 2014







