)
To set the stage, Messina described Italian public broadcaster RAI — Radio Televisione Italiana present challenges:
First, the cost for new storage-hungry media formats (4K, UHDTV) is exploding, driven by an increase in content quality, frame rate, dynamic range and others.
Second, the distribution of publication channels is diversifying. For example, extraterrestrial satellites, the Internet and mobile channels are now as critical to RAI’s business as traditional mediums.
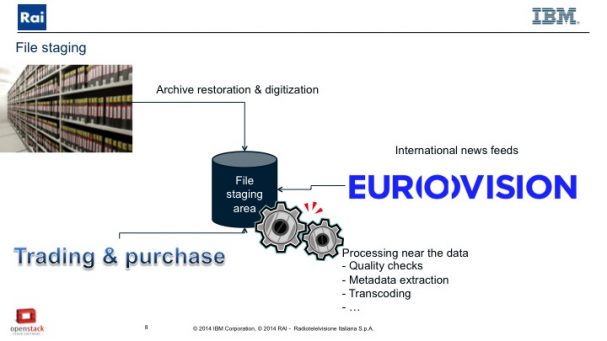
Third, the management of historical media is inconsistent, complex, and expensive. Not only must digital restoration and historical media archiving enforce standards of quality and accessibility, but broadcasters must factor in storage and processing capabilities for their archived digital media.
We’re talking about millions of hours of video. And we need to be able access it instantly.
Finally, the mobile and distributed workforce pervades. RAI needs to enable employees to collaborate and manage content across geographically separated sites throughout the media production cycle.
So Why Use Docker and Swift?
Analyzing, transforming, and processing very large amounts of data on traditional storage systems requires you to move the data objects from storage to compute. This is costly both in terms of time spent and resources used.
Using Docker-powered Swift clusters, along with storlets[1] — a piece of computation that runs inside the Swift cluster and gets executed inside the Docker container — it is possible to move the media workflow near the storage.
The benefits of his approach include:
- First, co-locating compute inside storage reduces critical bandwidth. Sending RAI’s very large media files back and forth between storage and compute strained their resources. Using Docker and Swift meant fewer bytes transferred over their network.
- Second, RAI was able to preserve infrastructure on the client side and kept costs low by consolidating extensive processing with storlets.
- Third, Docker and Swift storlets provide improved monitoring and tracking, making it easy to track object transformations.
A member of the audience asked: why is this workflow better done in Swift than further upstream? Why complicate Swift by adding all this functionality, instead of running alongside of Swift in the Datacenter, or before the ingest?
Messina replied by saying that Metadata enrichment happens again and again during the content lifecycle. It doesn’t simply stop once you have the file. It is important for media production to be able to extract new metadata on demand. It is a lively and continuous operation. As new algorithms arise, as new tools are developed, and as media quality improves, we need to extract the metadata in Swift.
An Example: Loudness
Messina then walked the audience through a demonstration of how Docker, Swift, storlets and the storlet engine — the software that manages storlets and pipes Swift’s data in and out of the storlet running in the docker container — manages the processing and transformation of one important quality parameter for their digital media: loudness.
Since programs are produced by different parties that apply different criteria, broadcasters must be prepared for programs to be recorded at various levels of loudness. This can cause serious quality problems for clients. Imagine watching a television program that cuts to an extremely loud advertisement.
We have to check the conformance of the content when it is ingested, as well as when it is edited.
The first step in any quality check happens in the staging area, where Messina showed a list of all projects — units of production awaiting any processing or transformation job. Each project is implemented in a Swift container in the backend.
Next, Messina opened a project, to show the files (in RAI’s case, all the files are in the Material Exchange Format (MXF) .mxf) in a dashboard where the users can search by metadata, delete files, ingest content, process edits or transformations, and run any checks.
Then, he uploaded a new video file into the project and checked to see if it was the correct loudness. While putting the file in the container, storlets ran automatically — one of which extracted the metadata (aspect ratio, loudness, and other parameters) of the video.
Messina asked the audience to imagine applying this normalization process not just to one file, but to 100 or 200 files at once. He quickly executed a search for files that have a loudness beyond the bounds of a determined range using the metadata-based search in the Swift backend, then applied the loudness re-normalization process in a matter of seconds.
What Happens Behind the Scenes?
Eran Rom, of IBM Research explained how Messina and his team at RAI built the workflow.
- Step 1: File ingest
- 1a) Technical metadata calculation
- 1b) Loudness calculation
- Step 2: File Check
- Metadata search
- Step 3: Loudness re-normalization
In the backend, the loudness normalization storlet running inside the object node (server) where the file lives, calculates and re-normalizes the loudness level, and saves a new file with the correct loudness level. One can fix these files in place without any download.
We’re bringing code from the outside to run inside Docker containers on the storage system. It allows the user to control the underlying image where the storlet runs.
The flow to update the image of where a user’s storlets are going to run is a simple process.
- Pulling the image to be updated from the Docker registry
- Using standard docker tools (docker file), add FFMPEG on top
- Push the image back to the Docker repository
- Then the Swift storelet manager on the provider side deploys to the Swift nodes.
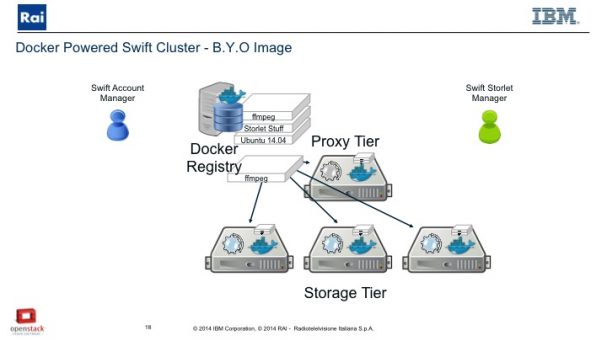
If we already have the base images deployed, we only have to deploy the layer of FFMPEG
Now we can go and run storlets on top of it.
Rom emphasized how easy it is to write a storlet and deploy it. We currently support only Java but it would be easy to add more language bindings by implementing a Java interface, packing it into a jar, and uploading it as a regular Swift object in a Swift object container.
Future Plans
Before taking questions, Rom and Messina outlined their future plans for Docker and Swift at RAI.
First, they will make a Docker-powered Swift cluster with the storlet engine and metadata search available for experimentation. Is this ready to play with? Not yet, but Rom was hopeful that something will be available for others to work on in the near future.
Second, they plan to increase the number of storlets, introduce additional processing steps to produce more metadata, and build an advanced search application on them.
Finally, they will continue to enrich the media prototype with additional storlet-based workflows.
To learn more about RAI and IBM’s work with Docker and Swift, see Messina and Rom’s entire talk at the OpenStack Summit in Paris.
Slides courtesy of
Eran Rom, Systems and Storage Researcher, IBM Research-Haifa
Alberto Messina, R&D Area Coordinator, RAI Radiotelevisione Italiana
[1] This paper describes research work on Storlets with the same underlying idea but different implementation. For example, the life cycle management is different, and the rule engine described in the paper are not used in this case.
- Kilo Update: Keystone - January 9, 2015
- Nova Updates – Kilo Edition - December 9, 2014
- Docker Meets Swift: A Broadcaster’s Experience - November 11, 2014







