)
OpenStack survey data shows that many industries beyond IT are finding the open source cloud-computing management platform an essential component of their businesses. Along with telecommunications, government, and retail, financial services is one of the industries showing the most significant growth in deployments of OpenStack technology.
As part of the recent OpenStack Summit in Sydney, Australia, Commonwealth Bank’s Quinton Anderson gave a short rundown of his company’s basic OpenStack deployment, which helps Commonwealth manage the data to help figure out what its customers really want and need.
Commonwealth is one of the larger banks in Australia, said Anderson and one of the largest banks in the world by market cap. His team started to look at maturing its approach to data management and machine learning four or five years ago and found that there were three levels of maturity their system needed to advance through. “You start with the basic process of experimentation, a first level of maturity,” he said. “You get some data in the correct place and you start to generate some experiments.”
The experimental process was interesting, said Anderson, and it helped his team learn a lot about data management. Taking the often brittle and scientific nature of these early experiments from lab to factory, he said, is the next step of maturity. “How do I get to the state where my experiments result in predictions, result in customizations of the way I engage with my customer and the way my product systems behave, in a way that is reliable, operational, (and) productionized?”
Anderson’s team spent a lot of time figuring out how to deal with data labels as well as with data and model monitoring. The third level of maturity, then, is deciding how to impact the customer experience and the way the business operates as a result. “We call this third level of maturity decisioning,” Anderson said.
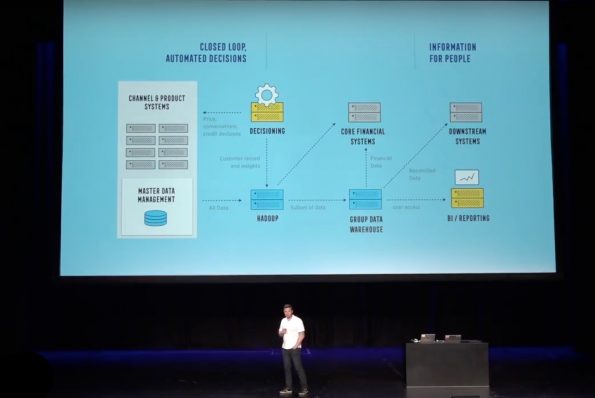
The logical representation of Commonwealth’s decisioning system is above. It has two major use cases, one for closed loop, automated decisions and one that focuses on information for people. The automated system integrates analytical and data management processes into the product system that impacts what the customers see, when they see it, and how the company engages with those customers as a result. The second use case is for internal staff to know what’s going on with the business and its customers’ businesses and lives to help staff make informed decisions.
The team started with some fairly large Hadoop clusters, with some fairly traditional data warehousing technology. The Hadoop clusters were initially based on physical servers in Commonwealth’s data centers. “That worked in the beginning,” Anderson said, “but as you can imagine, (it) comes with a bunch of inherent constraints, which we needed to work through.”
Obviously, said Anderson, the cost of upgrading and changing this initial setup was not good for the company or developers. “We departed on a journey to try and cloud-enable some of these technologies, said Anderson, “so that the process of experimentation was a lot faster for our business, but also a lot cheaper, and a lot more deterministic.”
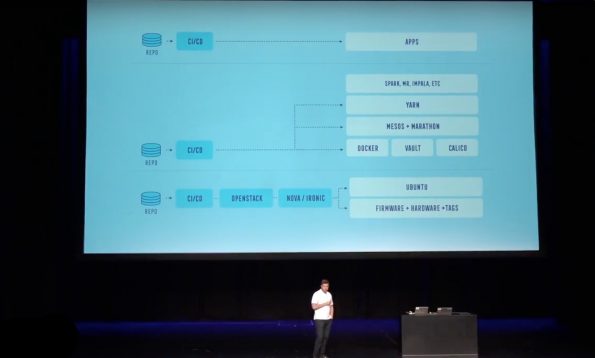
The technology stack Commonwealth decided on is fairly typical. “We’ve got OpenStack at the bottom, and we run Ironic for that,” Anderson said. “The reason (we used) Ironic, for the initial set of use cases, is the (ability to do) big data processing; staple services want to be close to the disk. Also, increasingly as we move into micro-services, the VM abstraction is, in a lot of ways, uncomfortable if you want to drive immutability.”
The team runs Ubuntu on top of that, with Docker for containers and Calico for container networking. They also run Vault for secrets-management, as well as Mesos and Marathon for resource orchestration with a platform-as-a-service API. “On top of that, we run our big data applications, and finally end applications on top of that,” Anderson said. “This is a fairly typical stack… It’s a container cluster on top of a cloud.”
Anderson feels that what makes their implementation unique is how it focuses on continuous delivery at all layers of the stack. They also focused on versioning through codification, along with immutability through all layers. “For us, an upgrade of an operating system, or even changing the permissions on a folder inside an operating system in an underlying host is not a matter of SSH-ing into a box,” he said, “but rather updating a declarative form of the environment, and issuing a pull request, and allowing the tooling to make all the changes on your behalf.
That is true for the operating system, for containers and container clusters, for monitoring, orchestrators, alerting and absolutely everything in the system. “We use the same basic interaction pattern,” Anderson said, “which is versioning through codification, automation through codification, and continuous delivery, applying the changes off the back of that.”
The workflow separates out a module repository, which has the source code, the tests, the pipeline, the pool, and so on, for each particular module (which can be a container in the control tier, an app, or anything executing in an environment. “We separate those module repos from our environment repos,” said Anderson. “The environment repos contain declarative forms of the environment… (and) we try and ensure that these things are strongly versioned.”
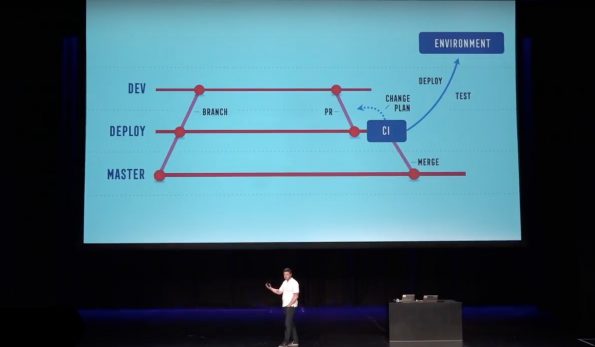
There’s a declarative form of the deployment’s environment sitting on Master, which represents what’s running in the designated environment. Anderson can fork the repository from that point, making changes like upgrades, host introduction, deploying new clusters or applications, and the like, and then issue a pool request against the deploy branch. “The pool tooling will then generate a change plan,” he said, “and attach that to the pool request for me. You can think about this workflow as being pretty similar to HashiCorp’s Terraform, where it’s going to generate a change plan, but we’ve integrated this very strongly into GitHub, and therefore into version control.”
Several “bots” make reviews of any requested changes to make sure there’s enough environmental capacity, that no changes are too risky, and that they’re being deployed into the correct environment. They can also check for any junior developers who shouldn’t be pooling against production, said Anderson. There are also manual pool checks, too, where an actual human will look at proposed changes. “When the pool request merges,” he said, “the tooling goes off and applies the changes into the environment. You can think about what’s sitting on the deploy branch as being, effectively, the desired state, what’s sitting on master as being the actual state or the previous state. The tooling is going to go off and apply those changes to the environment by making API calls to Nova or Marathon, HashiCorp Vault, so forth. Once the changes have completed, it will then merge the new declarative form back onto Master.”
If there are any failures in the deployment, it’s fairly easy to get back from that point. “You’ve got desired state,” said Anderson. “You’ve got actual state. You’ve got an interim desired state convergence, which are in your logs. Of course, as you do smaller and smaller changes, that problem becomes less and less.”

What the team has done, then, is compose a large number of open-source projects together, with OpenStack as the foundation, in order to generate Commonwealth’s business outcomes. “We believe strongly that versioning through codification gives us an absolutely best-case we have to change all of those different levels of compositions, and therefore services and systems, in a sustainable manner over time,” said Anderson. “It allows us to recreate environments. It allows to build automation in a scalable manner. It allows us to recreate the environments, and therefore have automated testing, which is the basis on which safe change can take place.”
Anderson started with OpenStack as the basis for this approach, in order to even just do immutable and codified access of their infrastructure. “OpenStack Ironic is the first place you start,” he said. “Then, it’s a buildup from there.”
Over time, though, Anderson’s team will take the same approach to its public cloud environments to match it’s overall hybrid cloud strategy. “In the analytics space then, R is a major tool of use from our data scientists,” he said. “(We’re using) Hadoop, (and) increasingly Spark, as a part of the ecosystem. We still have a fair amount of HD affairs from a stateful workload perspective, and increasingly Cassandra. (We’re) starting small, but in increasing amount of TensorFlow coming in.”
The team uses Mesos primarily in the stateful space right now, and increasingly in the stateless space Kubernetes, as well. Calico offers container networking in a simple, well-integrated way with the various existing networking environments across different cloud providers. The team uses Docker as their containers, and Ubuntu as the hosts. “This provides us not only a nice environment for our stateful and analytics workloads,” said Anderson. “It also, increasingly, is providing us with a nice environment to host different types of workloads (and) pure micro-services. It started with just data science dashboards, Python user interfaces, Python dashboards, etc. and increasingly is going into our more web-facing workloads and micro-services.”
Anderson calls OpenStack an important foundation for building Commonwealth Bank’s internal systems. “It’s been a really interesting journey to start with composing OpenStack and some basic container environments,” he said, “and work through the entire process of composing the rest of these open source technologies, using a strong approach of getting the basics right first.”
Catch the whole keynote talk below.
- Yes it blends: Vanilla Forums and private clouds - November 5, 2018
- How Red Hat and OpenShift navigate a hybrid cloud world - July 25, 2018
- Airship: Making life cycle management repeatable and predictable - July 17, 2018










