)
Although the European Organization for Nuclear Research occupies a relatively modest patch of land on the French-Swiss border, the scope of CERN’s research is big — from the Higgs boson (aka “God particle”), anti-matter and dark matter, to extra dimensions – and the amount of data generated is truly vast.
Since 2014, the CERN Open Data portal, which runs on OpenStack, has been making it available for high schoolers, data scientists and armchair physics buffs. The most recent information made public in late 2017 includes a petabyte of data, including sets related to the discovery of the Higgs boson glimpsed through the Large Hadron Collider.
Superuser talks to Tibor Simko, technology lead behind the CERN Open Data portal, about the backend as well as the future of the project.
CERN’s Open Data Portal runs on OpenStack — what can you tell us about the backend?
The CERN Open Data portal was first released in 2014. The portal ran on about eight virtual machines on the CERN OpenStack cloud infrastructure. The machines were managed by Puppet. The architecture includes the front-end load balancing servers running HAproxy, dispatching user requests to the caching servers running Nginx that either serve the cached content, or, if needed, dispatch the user request further to the CERN Open Data web application itself. The application runs on top of the Invenio digital repository framework that further uses Redis caching service and SQL relational database services.
The CERN Open Data portal hosts several thousands of records representing datasets, software, configuration files, documentation and related supplementary information released as open data by the LHC experiments. The total amount of released data represents more than 1400 Terabytes. The data assets themselves are stored on the CERN EOS Open Storage system. The CERN Open Data portal relies heavily on the EOS distributed storage system regarding its backend data storage needs.
What were the resources at your disposal and scope of the portal project when it launched and what are they now?
On the application side, the CERN Open Data portal recently underwent a major change of the underlying repository framework, from Invenio 2 to Invenio 3. We have upgraded our data model, the user interface and improved the faceted search experience. The new portal was released in December 2017.
On the infrastructure side, we have been early adopters of container technologies and used Docker for the CERN Open Data portal development since its beginning. We are now using containers also for the portal production deployment itself using the OpenShift platform.
Besides the changes in the portal technology and deployment, the amount of the open data released by the LHC experiments has grown in an exponential manner. For example, the CMS collaboration released a part of the 2010 datasets of about 30 TB in 2014 initially; the 2011 datasets of about 300 TB were released in 2016, and the 2012 datasets that we just released were about 1 PB in size!
The CERN Open Data portal’s storage component relies heavily on the scalability of the EOS storage system to host large amounts of released open data. Since the CERN EOS system manages over 250 Petabytes at CERN overall, the amount of the open data pool remains moderate when compared to the regular daily usage by the physicists.
What are the challenges particular to planning an open-access cloud like this one?
The challenges were of diverse nature.
First, we needed to organize the datasets, the software, the configuration, the documentation and the auxiliary information so that it would be understandable by non-specialists. We were working closely with the LHC experiments on the data organization and management.
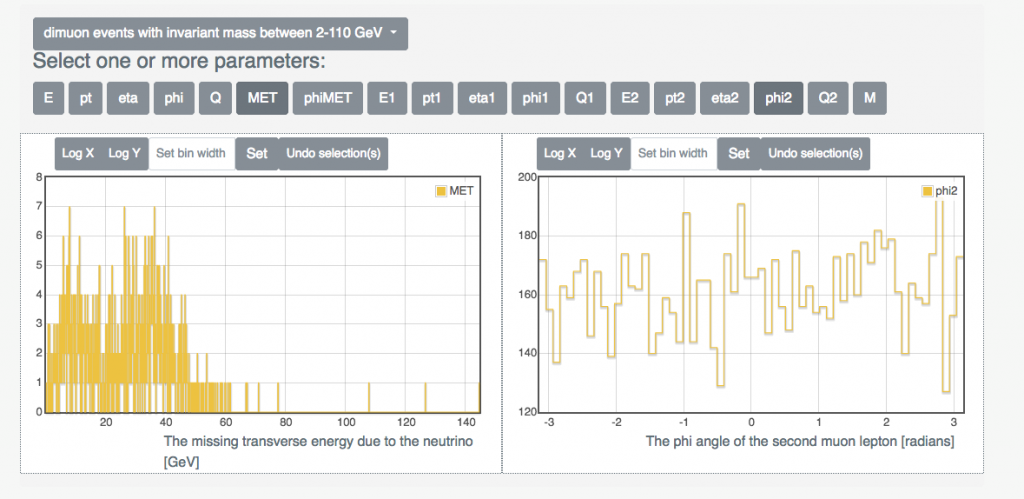
Second, we had to present the research data to a non-typical audience consisting of data scientists, high-school students and the general public. We’ve integrated tools that permitted to explore the data via event display visualization or basic histogramming; we’ve also provided detailed guides on how to run more advanced physics analyses on the released primary datasets.
Third, we had to design a scalable system that would be capable of serving possibly thousands of parallel user requests at a time, following the usage peaks coming after widely-covered press releases or social media events.
What can you tell us about future plans?
We plan to improve the discoverability of the CERN Open Data material by exposing our datasets using general standards such as JSON-LD with schema.org. We plan to publish REST API interfaces to enable users to easily write applications against the portal.
We are looking forward to forthcoming open data releases from LHC experiments. We are excited to host a first non-LHC experiment open data issued by the OPERA collaboration.
Finally, we plan to facilitate working with the open data by providing richer and more easily runnable analysis examples.
How did your previous work on the Invenio digital library platform inform this project?
The Invenio digital library framework has been developed at CERN to run services that were originally oriented towards managing articles, books, preprints, theses, audios, photos, videos. Progressively, the experimental particle physics collaborations have been using the open access publications services to share the supplementary material to publications, such as numerical “data behind plots,” the plotting macro snippets, or the event display files. This brought a natural evolution of Invenio’s focus from targeting the “small data” domain towards the “big data” domain.
We have been trying to describe and capture the structured information about the whole research process, including the experimental collision and simulated datasets, the virtual machines, the analysis software and the computational workflows used by the physicists to analyze the data that all together produce the original scientific results and publications. Capturing the research analysis process and its computational workflows in order to make the science more easily reproducible and reusable in the future light of new theories is an exciting topic that coherently subscribes to the wider evolution of the open access movement through open data to open science.
Anything else you’d like to share?
Before joining CERN, I worked in the field of computational plasma physics, all the while being involved with parallel software programming activities and side projects. I feel therefore particularly enthusiastic and privileged to work at CERN in the field of open science that bridges computing and physics. We’re trying to foster better open and reproducible science practices through offering better open science software tools that would assist the particle physicists researcher in their data analysis computing needs.
About Tibor Simko
Tibor Simko holds a PhD in plasma physics from Comenius University Bratislava, Slovakia and from the University of Paris Sud, France. He joined CERN to work as a computing engineer where he founded the Invenio digital repository framework. Simko later worked as a technology director of INSPIRE, the high energy physics information system. He now leads the development of the CERN Analysis Preservation, CERN Open Data and the Reusable Analyses projects. His professional interests include open science and reproducible research, information management and retrieval, software architecture and development, psychology of programming, free software culture and more.
You can find him on Twitter and GitHub.
- OpenStack Homebrew Club: Meet the sausage cloud - July 31, 2019
- Building a virtuous circle with open infrastructure: Inclusive, global, adaptable - July 30, 2019
- Using Istio’s Mixer for network request caching: What’s next - July 22, 2019










