)
This article originally appeared on Oracle’s Blog. Dave is Sr. Principal Software Engineer at Solaris, Oracle, with a lot of background in networking and system management. You should follow him on Twitter.
One of the signature features of the recently-released Solaris 11.2 is the OpenStack cloud computing platform. Over on the Solaris OpenStack blog the development team is publishing lots of details about our version of OpenStack Havana as well as some tips on specific features, and I highly recommend reading those to get a feel for how we’ve leveraged Solaris’s features to build a top-notch cloud platform. In this and some subsequent posts I’m going to look at it from a different perspective, which is that of the enterprise administrator deploying an OpenStack cloud. But this won’t be just a theoretical perspective: I’ve spent the past several months putting together a deployment of OpenStack for use by the Solaris engineering organization, and now that it’s in production we’ll share how we built it and what we’ve learned so far.
In the Solaris engineering organization we’ve long had dedicated lab systems dispersed among our various sites and a home-grown reservation tool for developers to reserve those systems; various teams also have private systems for specific testing purposes. But as a developer, it can still be difficult to find systems you need, especially since most Solaris changes require testing on both SPARC and x86 systems before they can be integrated. We’ve added virtual resources over the years as well in the form of LDOMs and zones (both traditional non-global zones and the new kernel zones). Fundamentally, though, these were all still deployed in the same model: our overworked lab administrators set up pre-configured resources and we then reserve them. Sounds like pretty much every traditional IT shop, right? Which means that there’s a lot of opportunity for efficiencies from greater use of virtualization and the self-service style of cloud computing. As we were well into development of OpenStack on Solaris, I was recruited to figure out how we could deploy it to both provide more (and more efficient) development and test resources for the organization as well as a test environment for Solaris OpenStack.
At this point, let’s acknowledge one fact: deploying OpenStack is hard. It’s a very complex piece of software that makes use of sophisticated networking features and runs as a ton of service daemons with myriad configuration files. The web UI, Horizon, doesn’t often do a good job of providing detailed errors. Even the command-line clients are not as transparent as you’d like, though at least you can turn on verbose and debug messaging and often get some clues as to what to look for, though it helps if you’re good at reading JSON structure dumps. I’d already learned all of this in doing a single-system Grizzly-on-Linux deployment for the development team to reference when they were getting started so I at least came to this job with some appreciation for what I was taking on. The good news is that both we and the community have done a lot to make deployment much easier in the last year; probably the easiest approach is to download the OpenStack Unified Archive from OTN to get your hands on a single-system demonstration environment. I highly recommend getting started with something like it to get some understanding of OpenStack before you embark on a more complex deployment. For some situations, it may in fact be all you ever need. If so, you don’t need to read the rest of this series of posts!
In the Solaris engineering case, we need a lot more horsepower than a single-system cloud can provide. We need to support both SPARC and x86 VM’s, and we have hundreds of developers so we want to be able to scale to support thousands of VM’s, though we’re going to build to that scale over time, not immediately. We also want to be able to test both Solaris 11 updates and a release such as Solaris 12 that’s under development so that we can work out any upgrade issues before release. One thing we don’t have is a requirement for extremely high availability, at least at this point. We surely don’t want a lot of down time, but we can tolerate scheduled outages and brief (as in an hour or so) unscheduled ones. Thus I didn’t need to spend effort on trying to get high availability everywhere.
The diagram below shows our initial deployment design. We’re using six systems, most of which are x86 because we had more of those immediately available. All of those systems reside on a management VLAN and are connected with a two-way link aggregation of 1 Gb links (we don’t yet have 10 Gb switching infrastructure in place, but we’ll get there). A separate VLAN provides "public" (as in connected to the rest of Oracle’s internal network) addresses, while we use VxLANs for the tenant networks.
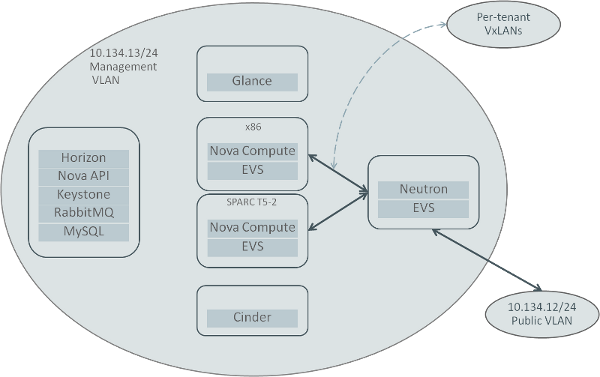
One system is more or less the control node, providing the MySQL database, RabbitMQ, Keystone, and the Nova API and scheduler as well as the Horizon console. We’re curious how this will perform and I anticipate eventually splitting at least the database off to another node to help simplify upgrades, but at our present scale this works.
I had a couple of systems with lots of disk space, one of which was already configured as the Automated Installation server for the lab, so it’s just providing the Glance image repository for OpenStack. The other node with lots of disks provides Cinder block storage service; we also have a ZFS Storage Appliance that will help back-end Cinder in the near future, I just haven’t had time to get it configured in yet.
There’s a separate system for Neutron, which is our Elastic Virtual Switch controller and handles the routing and NAT for the guests. We don’t have any need for firewalling in this deployment so we’re not doing so. We presently have only two tenants defined, one for the Solaris organization that’s funding this cloud, and a separate tenant for other Oracle organizations that would like to try out OpenStack on Solaris. Each tenant has one VxLAN defined initially, but we can of course add more. Right now we have just a single /24 network for the floating IP’s, once we get demand up to where we need more then we’ll add them.
Finally, we have started with just two compute nodes; one is an x86 system, the other is an LDOM on a SPARC T5-2. We’ll be adding more when demand reaches the level where we need them, but as we’re still ramping up the user base it’s less work to manage fewer nodes until then.
My next post will delve into the details of building this OpenStack cloud’s infrastructure, including how we’re using various Solaris features such as Automated Installation, IPS packaging, SMF, and Puppet to deploy and manage the nodes. After that we’ll get into the specifics of configuring and running OpenStack itself.
Photo by fornax // CC BY NC SA
- Building an OpenStack Cloud for Solaris Engineering, Part 1 - August 28, 2014







