)
Success for an OpenStack architect means taking the long view, say Vinny Valdez and Vijay Chebolu, both from Red Hat. They outline an approach to designing an enterprise OpenStack cloud that looks good up close, too.
The role of the architect in OpenStack is less siloed, more flexible than in traditional IT environments, they say. These architects need to consider more frequent builds, maybe daily or weekly, and ways to enable their users to completely be self-serviceable. Everything should be API first, they add, and operations should be repeatable and improveable, rapidly.
Discovery is the architect’s breakfast – don’t skip it
OpenStack architects often face pressure to just get things up and running – but the pair say ignore the discovery process at your own peril.
Valdez, a senior principal cloud architect, says many fellow architects have the attitude “I was told to implement something [so] I’m going to do it.” But the reality is that the technical implementation details are ultimately driven by business, he says.
“We can put something together quickly — we can throw Devstack down or Packstack or whatever but it’s not going to be an optimal solution to the business needs.” Thinking ahead about the implications for service-level agreements (SLAs), for example, can reduce later headaches.
They offered a break down of the discovery process— understanding business objectives, technical objectives and technical architecture — to streamline your work.

“It’s difficult to get all these stakeholders together so plan your session when you’re collecting other requirements,” says Chebolu, a practice lead in Red Hat’s cloud infrastructure team. Only by narrowing down the business and technical objectives, you can arrive at the technical requirements, he says. Those first two steps of the discovery process should lead to arriving at a technical architecture that will work with OpenStack over time.
“Start small and use an incremental approach, building a minimum viable product (MVP) first and then iteratively grow that to cover more use cases,” he says. “OpenStack releases every six months so you don’t want to plan for something that’s required two years from now.” Planning your upgrades several release cycles into the future — forklift? rebuild? partial? — is also essential.
The Discovery Channel, part 1
Here’s their walk-through of the process with a mock project.
Start with why:

Move to what:

Then it’s time for how:

Here’s where things get a bit more interesting for the architect, as various “must-haves” come on board:

Discovery Channel, Part 2: Sample architectures
Now that you’ve digested all that information, you can design a basic cloud structure.
"This is a conversation that occurs with our customers. We would provide them a proposal for the solution to the different needs that they’ve given to us and the priorities. We may propose several different architectures…We want to start small, with a minimum viable product first," Valdez says.
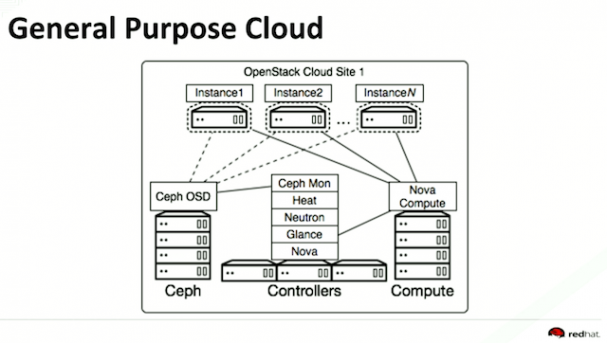
"This is probably the smallest production cloud you want to deploy with OpenStack," says Chebolu. "You want to understand if the enterprise is going to adopt OpenStack, then learn from it and actually can make it work. Once you have this up and running and you understand what OpenStack is, you design for the bare minimum use cases. Then you expand upon it to add more functionality."
The goal here is taking the use cases that and coming up with four proposed architectures and see what makes sense and how you want to deploy, Chebolu says.
For example, one of the requirements in the mock-up was that the company wanted OpenStack deployed to be dual purpose. One for general purpose compute but also better performance and network-function virtualization (NFV) workloads. Here’s basic set-up for that:
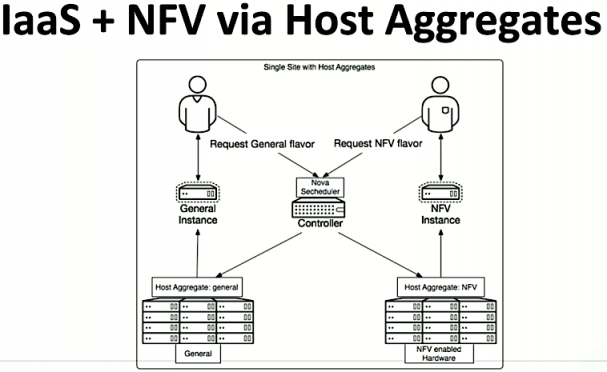
Then it’s time to move on to automated deployment.
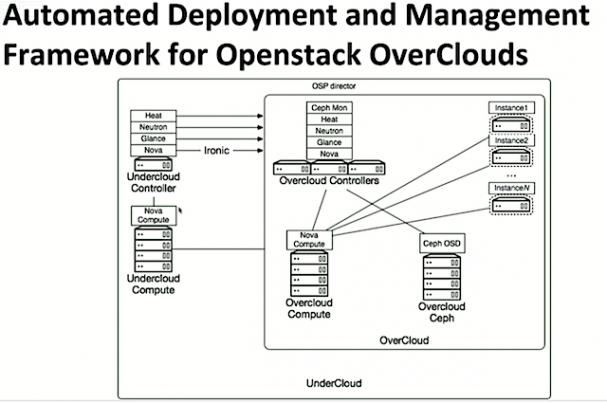
The outer box is the under cloud — or the initial Open Stack environment as it’s deployed. Rather than deploying a set of instances and networks that would represent your virtual environment, it interacts directly with bare metal using the Nova Ironic driver. Nova typically is your hypervisor that has a driver to Libvirt, but in this case using a Triple O it’s going to manage bare metal via Ironic. Glance provides the OS images and Ceph is recommended for storage.
Going big with multi sites
Using a real-life customer deployment, the pair shared this set-up for a multi-site cloud:
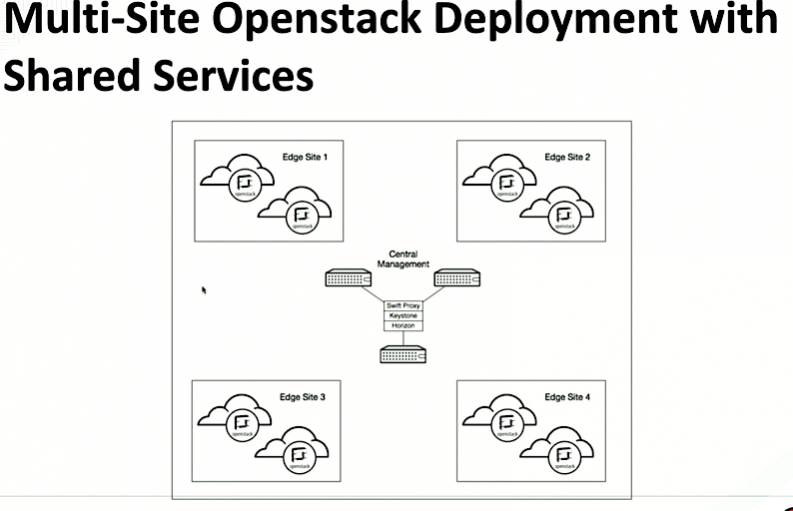
There are four edged sites that have some sort of service with the customers — it could be content, for example, Valdez says. Within each site there’s a fill-over regional environment of OpenStack. In this case they’re sharing management services Keystone, Horizon and Swift for example. This is is one way to do it, though, he says, it adds a bit of complexity.
But make your upgrades easier
In the above example, there are eight clouds, all tied to a common management pool. What’s the best way to keep them in-step with OpenStack’s six-month release cycle without causing any impact or down time?
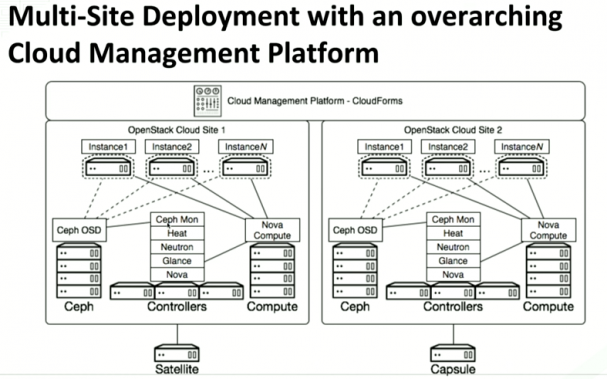
The key is to enable some sort of cloud management platform. "In this case, there are two independent regions…"says Valdez. "These are operating independently with something like a cloud management platform you can actually expose that to your end users which has its only API, its own UI and in this case you can define sets of instances that could potentially deploy to either region, among other things."
Operations
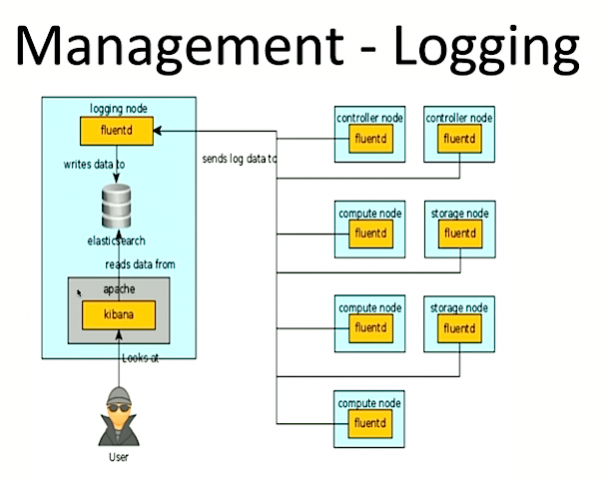
"One of the common things you want to know is when an OpenStack fails," Cebolu says. You want to know when a service is misconfigured, it’s not optimal. You also want to know when operator service is overloaded is not functioning properly."
A few tools for debugging OpenStack:

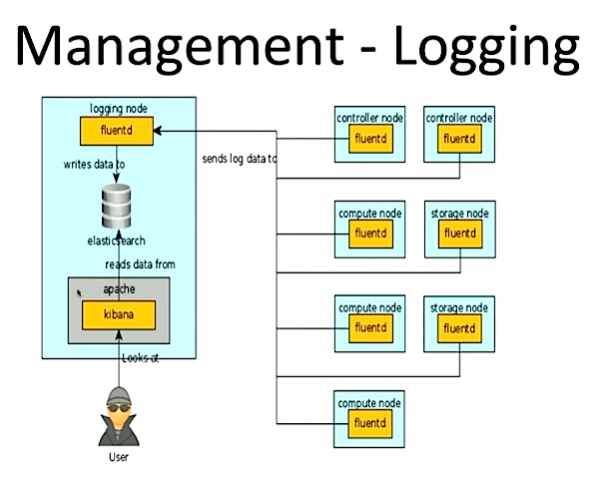
The pair say they regularly use fluentd because it’s highly scalable and, unlike Elasticsearch, it’s easier to build into the system. Here’s a sample set up:
What about monitoring tools?
Here are some of the more popular ones:

And here’s their sample set up:
Red Hat is working on its own tools — available now in tech preview and expected to land with the next OpenStack release.
"One of the challenges we see is that it’s difficult to operate an OpenStack environment," Chebolu says. "Our hope is that we actually build these open source tools and make it easier as an operator to run these clouds."
Chebolu and Valdez teamed up for a session at the Summit Tokyo. Catch the complete 40-minute talk on the OpenStack Foundation’s YouTube channel.
Cover Photo // CC BY NC
- OpenStack Homebrew Club: Meet the sausage cloud - July 31, 2019
- Building a virtuous circle with open infrastructure: Inclusive, global, adaptable - July 30, 2019
- Using Istio’s Mixer for network request caching: What’s next - July 22, 2019










