)
Kubernetes, RDMA and OpenStack? It is actually quite like oil, balsamic vinegar and bread. Done right, it’s really tasty!
This blog describes how we get RDMA networking inside Kubernetes pods that are running inside OpenStack VMs. Moreover, we then make this available on demand via Azimuth.
Why Kubernetes and OpenStack?
When you want to create a Kubernetes cluster on some hardware, you need a way to manage that hardware and the associated infrastructure. OpenStack gives you a nice set of APIs to manage your infrastructure.
StackHPC has been using OpenStack to manage the storage, networking and computing for both virtual machines and baremetal machines. Moreover, StackHPC knows how to help you use OpenStack to get the most out of your hardware investment, be that maximum performance or maximum utilization.
K8s Cluster API Provider OpenStack
We have always tried to treat Kubernetes clusters as cattle. We started that journey with OpenStack Magnum.
Recently we have started building a new Magnum driver that makes use of K8s Cluster API, its OpenStack Provider, and the K8s image builder.
The first part of that journey has been wrapping up our preferences in the form of our CAPO helm charts that make use of Cluster API and a custom operator that installs add-ons into those clusters. We have an ongoing upstream discussion on converging on a common approach to the add-ons. Cluster API brings with it the ability to auto-scale and auto-heal.
The cluster template has “batteries included”. Specifically, the add-ons include GPU drivers, network card drivers, and making use of Cloud Provider OpenStack. We also include Grafana, Loki and Prometheus to help users monitor the clusters.
Putting this all together, we now have a K8s native way to define cluster templates and create them as required on OpenStack.
SR-IOV with Mellanox VF-LAG
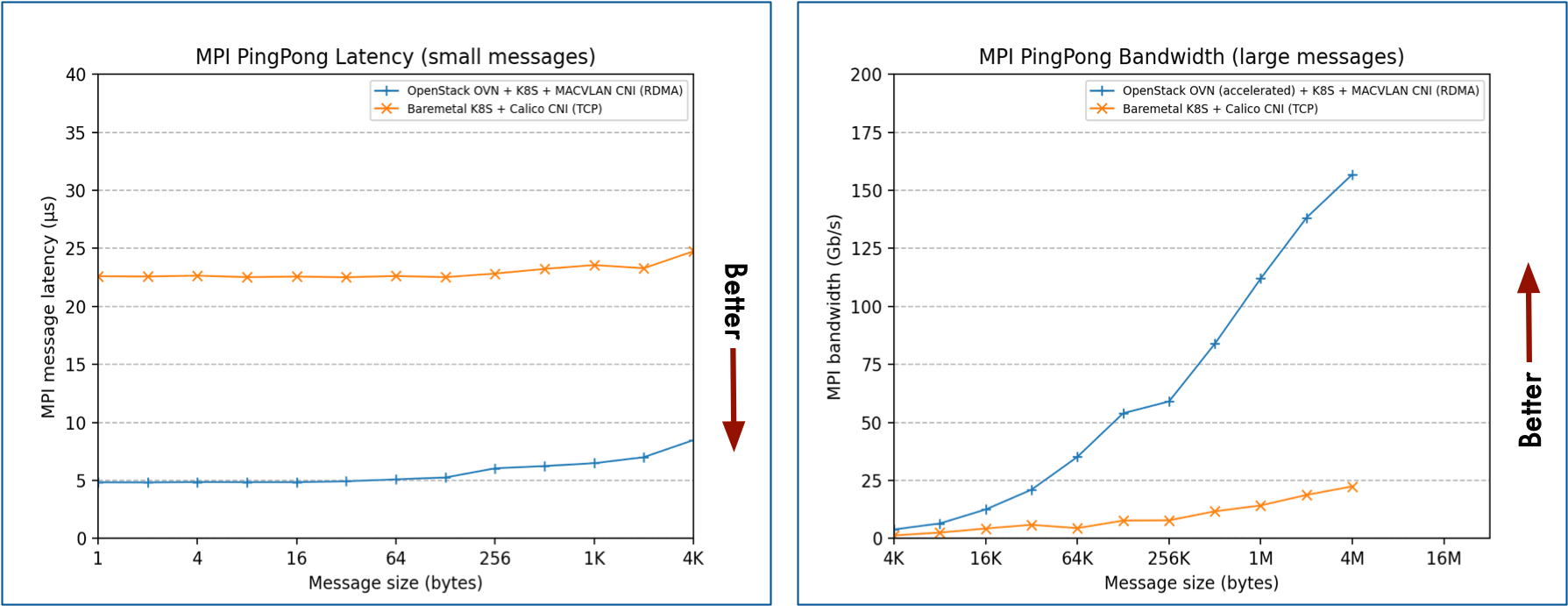
So Cluster API lets us create k8s clusters on OpenStack. We make use of VF-LAG to get performant RDMA networking within VMs. On a single ConnectX-5 using bonded 2x100GbE on a PCI Gen 4 platform, inside VMs, we can see RDMA bandwidths of over 195Gbs, TCP bandwidth of around 180Gbs, with MPI latency of under five microseconds.
For more details please see our presentation from KubeCon Detroit, co-presented with the team from Nvidia Networking:
Now we have the VMs working nicely, the next thing is getting this working inside VMs.
RDMA using MacVLAN and Multus
To use macvlan, we make use of the Mellanox network operator: https://github.com/Mellanox/network-operator
Using the operator, we make use of multus to allow pods to request extra networking. We then use MacVLAN to provide the pods with a network interface with a random MAC address interface, with an appropriate IP such that it can access other pods and external appliances that might need RDMA. In addition, we make use of the shared device plugin, to ensure pods get access to the RDMA device without needing to be a privileged pod with host networking. Finally, OFED drivers are installed using a node selector to only target hosts with Mellanox NICs.
To prove this all works we need to run some benchmarks. To make this easier we have created an operator kube-perftest. The operator uses iperf2, ib_read_bw, ib_read_lat, MPI ping pong and more to help us understand the performance. In particular, kube-perftest can request an additional multus network, such as the above MacVLAN network.
Self-Service RDMA enabled Apps using Azimuth
To make it easy to create K8s using the templates above we make use of Azimuth to help create clusters simply via a user interface, that comes with working RDMA.
Reposted with permission from StackHCP, the original article can be found here.
- Kubernetes, RDMA and OpenStack - October 19, 2023
- StackHPC at Vancouver OpenInfra Summit - October 8, 2023
- What’s on the horizon for high-performance computing - June 8, 2018










