)
Much has been said about the relationship between OpenStack and containers.
Thierry Carrez, OpenStack’s VP of engineering, provides his take with a nod to characters of the hit TV show “Silicon Valley.” You can catch him talking more on this topic (and ask him questions!) at upcoming events, including OW2 and OpenStack Days in Taiwan, Japan, China, U.K. and Nordic region. Below is an edited transcript of his recent talk at the Boston Summit.
When a new technology appears, it creates confusion as people try to wrap their heads around it. OpenStack was becoming mainstream in 2011, then it was containers in 2014, Kubernetes in 2016 and every single time the same thing happens. People think the new technology is set to replace everything else —as if a single technology can solve all of the world’s problems. The rise of containers and container orchestration systems has created a lot of confusion, especially with respect to OpenStack, the previous “hot” technology.
“If containers are replacing VMs and OpenStack is VM-centric does that mean OpenStack is not relevant anymore?” You also might ask why deploy OpenStack, if all you want to do is cloud-native? Or, for people who actually understand that those aren’t different technologies, there’s still plenty of confusion about whether OpenStack runs containers, or is it running on containers, etc.
These aren’t hypothetical questions. They are questions I hear all the time. To clarify the situation, I’d like to introduce a set of personas. Personas are a tool used in user experience studies — they put a face and profile on a typical user and describe his or her life to highlight their needs.
The Cast
Here are three — slightly overlapping — personas:

The first one, let’s call him Dinesh, is the application developer. Dinesh writes the applications that run your business. He cares mostly about speed: Speed to design, speed to develop, speed to deploy, speed to market. He also likes to use the latest tools, because they make him more efficient and keep him relevant on the job market. Today, Dinesh is looking into 12-factor applications and serverless technologies.
Dinesh doesn’t want to bother too much about infrastructure. He doesn’t want to deploy any servers, doesn’t want any difference between his development environment, his test environment and his production environments that could introduce bugs in his applications. Finally, Dinesh does not obsess too much about cost or vendor lock-in. He loves Amazon Web Services (AWS), it’s very convenient and he’s happy with it.

The second persona is Bertram, the application operator. Bertram handles the deployment, monitoring and scaling of the apps that Dinesh writes. (These personas may overlap.) In some companies, the Dineshs and Bertrams share the same desks and offices. But in lot of companies they are slightly different roles, with different priorities — Bertram cares a lot about performance and reliability more than he cares about speed, for example. He’s the one on call, so he wants solid and proven tools because he doesn’t want to be caught at 10 p.m. on a Saturday because something caught fire in production. Bertram doesn’t want to micromanage infrastructure but he still wants to look under the hood to understand how it works, he still wants to understand enough to select the right technology. Finally, Bertram is concerned about lock-in, because he likes to pick the best technical tool and being locked reduces his options.

Our third persona is Erlich, the infrastructure provider — even in a serverless world, someone has to rack servers and that’s his job. Erlich might be operating a public cloud infrastructure and offering infrastructure resources to anyone around the world with a credit card, or he might be operating private cloud infrastructure and offering infrastructure services to people in a given organization, that doesn’t change his role much. Erlich doesn’t want to bother too much over specific work loads, he wants to provide generic programmable infrastructure so Dinesh and Bertram can do their jobs. His primary metric is cost. Erlich also cares about evolution — the ability to change his systems so they’re relevant for what comes along next.
The tech

So that’s our cast, now let’s talk about the tech: containers, Kubernetes and OpenStack. Containers are, at heart, a packaging format. They’re a convenient way to package applications with libraries and dependencies. They also offer pretty nifty deployment tooling, convenient ones that you can use to deploy in applications in relatively isolated environments. Docker’s contribution was bundling those namespace and control group kernel technologies together with that convenient tooling to make those tools accessible to everyone. With the success of Docker, we’ve also seen the rise of application marketplaces as more and more companies publish their applications under containerized formats. All of this makes containers extremely appealing to Dinesh.
Kubernetes is one abstraction level up from containers. It’s a way to describe your application using groups of containers, the role they have in the application, how to scale them, deploy them and maintain them semi-automatically. In a way, it’s a deployment platform for containerized applications. It’s great because it captures operational best practices from Google’s experience and embeds it in the way you describe those resources. It’s also good at managing application life cycle and scaling — scale up and down on demand, and handle things like rolling upgrades, etc. … Bertram loves Kubernetes because it encapsulates operational best practices and it’s also pretty solid. It’s open source, so he can look under the hood. It can be run on public or private clouds, so he’s basically free from lock-in. Containers are great for Dinesh, Kubernetes is great for Bertram, but neither of these solves problems for Erlich.
Erlich wants to provide programmable infrastructure for the Dineshs and Bertrams of the world. He has two choices: specific infrastructure or open infrastructure. Specific infrastructure works if Erlich is dead sure that everything that Dinesh and Bertram will ever want is containers and a container orchestration system like containers and Kubernetes. They’ll use that combination forever. If that’s the case, there’s little value in unnecessarily deploying on top of OpenStack resources. He can deploy a Kubernetes cluster on bare metal servers directly.

Open infrastructure is for when you want options. Bertram and Dinesh need access to containers and container orchestration systems, plus access to VMs, to bare metal machines, to Mesos clusters to Docker Swarm clusters and provide those options with shared networking and storage. For example, if they want to combine VMs, containers and other things, they have to be able to communicate and store and access data. You also want to provide advanced services, like object storage, or database-as-a-service. These make Dinesh more efficient, since he doesn’t have to reinvent object storage, and Bertram more efficient because he doesn’t have to micromanage databases.
You also want multi-tenancy and interoperability. Beyond that, you want burst capacity to a public cloud that can absorb it. You want scaling to millions of CPU cores. You want seamless operations — things like common log file formats or common configuration file formats. And you want whatever comes next. The framework you deploy must be capable of integrating with the technology that Dinesh and Bertram will want tomorrow. You don’t want to reinvent and reinstall everything for the next hot thing.
That’s what OpenStack provides. OpenStack’s goal is to give infrastructure providers a way to answer the needs of application developers and application operators. That means programmable infrastructure, VMs, bare metal machines, containers, container-orchestration engines (not just Kubernetes, but support for others, too), open infrastructure, the ability to plug-in services, interoperable infrastructure, compatible clouds that you can burst to and future-proof infrastructure.
You want the promise that the framework you’re deploying today will still be relevant tomorrow when new technology comes along — technology that today we don’t know what it will be — and you’ll be able to integrate it. Because, make no mistake, there will be something else. Kubernetes and containers are not the end of infrastructure technology. OpenStack is an integration engine that will be able to reuse the same framework tomorrow.
How they work together
Here are practical examples. The first is raw resources.
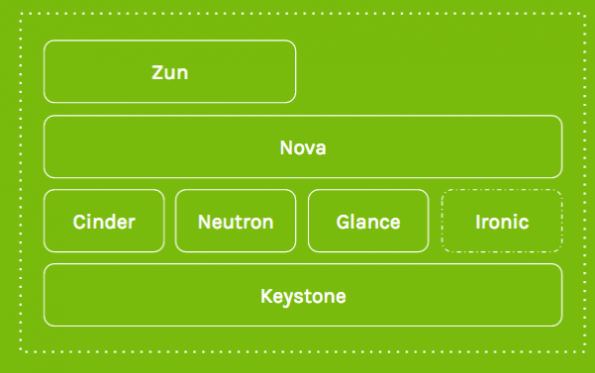
To provide access to raw resources, VMs or bare metal machines, you deploy Kubernetes on that and then you can deploy on containerized applications. To do that, you deploy a stack with Keystone for authentication, Cinder for block storage, Neutron for networking, Glance to store the disk images and Nova to provide the VMs you get those basic resources from.
If you want bare metal machines, then you would also deploy Ironic to drive access to those bare metal machines. This is OpenStack’s most basic use case: You provide raw infrastructures and it’s someone else’s job to deploy Kubernetes on top of it.
Now, if you want to have a Kubernetes cluster deployed directly, it’s more of a container orchestration-engine-as-a service. In that case, you’d directly have Kubernetes without having to deploy it yourself. You’d deploy the same stack with two more projects, Magnum and Heat. Heat for orchestration and Magnum to provide disk container orchestration-as-a-service system.
But at that point you might say, “Well, I just want to run a container, why are you deploying this Kubernetes cluster for me?” or “There’s this thing on Docker Hub and I just want to run it. How do I do that? Do I have to instantiate to VM and then install Docker on it, and then run whatever command on whatever?”
OpenStack has a solution for that. Essentially, you want OpenStack to absorb your container and run it. For that we have a container management service project called Zun. It lets you run any container and will provision a bare metal machine through Nova and Ironic, run it for you, then kill it when you’re done. It’s really as simple as “Zun create” the name of the container on Docker Hub. And all those options are backed with shared networking and storage.
The last example: let’s say you want to deploy is Kubernetes, but Kubernetes also needs identity management, access to block storage, access to networking and you might want to leverage all the drivers and plugins that we’ve developed in the OpenStack community, and give them access to it.
So to make sure Kubernetes doesn’t reinvent the wheel and leverage those projects to provide those functionalities, there’s a new project called Stackube, which has filed to become an official OpenStack project.
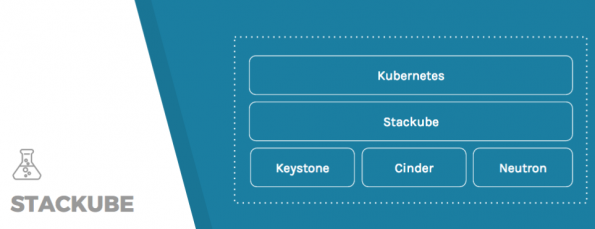
It bridges Kubernetes and provides plugins to Keystone, Cinder and Neutron. It’s also a truly multi-tenant Kubernetes installation using Hyper.sh technology to properly isolate the tenants — basically a Kubernetes multi-tenant distribution that reuses a number of OpenStack components.
How Erlich becomes Bertram
Now that you see how it all fits together, let’s switch things up. Why do people say we can run OpenStack on Kubernetes then? At this point you probably realize that OpenStack is a complex application…The deployment is very complicated because of all the moving parts and upgrades are difficult.
The idea of a deployment substrate to handle the complexity of upgrades and orchestration of the OpenStack application isn’t a new one. People have been running OpenStack on top of OpenStack with the TripleO project, for example. So we would run an OpenStack undercloud and use it to deploy the rest of the user accessible OpenStack overcloud instance.
Now if we get back to the technologies of what containers are — a packaging format, deployment tooling — it sounds like it could be useful to deploy OpenStack. You could use containers as a packaging format rather than relying on these 12 packages and use that convenient deployment tooling to simplify the deployment of OpenStack.
Those OpenStack packages can be published in a packaged format. A number of projects are exploring that space, including OpenStackAnsible, and the original Kolla… So a development platform for containerized apps that encapsulates operational best practices, manages application lifecycle and scaling. It can be useful to deploy, upgrade and maintain that OpenStack application. And, especially to simplify scaling and rolling upgrades, we could run OpenStack on a Kubernetes substrate — something that a number of projects are exploring.
There’s also the OpenStack-Helm project, a new initiative to produce a collection of Helm charts to deploy OpenStack that you can deploy with the Helm client onto a Kubernetes substrate. (These are two slightly different approaches for the same problem, which is leveraging Kubernetes to deploy the OpenStack application.)
In conclusion: containers are a packaging format with good tooling, ensuring the needs of application developers. Kubernetes is a best-practice application deployment system ensuring the needs of app operators. OpenStack is an infrastructure framework enabling all sorts of infrastructure solutions, ensuring the needs of infrastructure providers.

Containers can be aligned with OpenStack, providing infrastructure, allowing them to share networking and storage with other types of computer resources in rich environments. Kubernetes clusters can be deployed manually, or through a provisioning API on OpenStack resources, giving their pods the same benefits of shared infrastructure.
Finally, OpenStack operators can leverage container and Kubernetes technologies to facilitate their deployment and management of OpenStack itself. Containers can be aligned on OpenStack, providing infrastructure, allowing them to share networking and storage with other types of computer resources in rich environments. They are different, complementary technologies.
Catch his entire 25-minute talk below.
- Exploring the Open Infrastructure Blueprint: Huawei Dual Engine - September 25, 2024
- Open Infrastructure Blueprint: Atmosphere Deep Dive - September 18, 2024
- Datacomm’s Success Story: Launching A New Data Center Seamlessly With FishOS - September 12, 2024







