)
Dragonflow architecture consists of a Neutron plugin which maps the Neutron model to a new logical topology model and synchronizes this with local Dragonflow controllers which are distributed at each of the compute nodes using a pluggable distributed DB solution.
Unlike other projects, Dragonflow distributes the topology and the policy itself to the local end points (the local controllers) and compiles this topology into configuration and OpenFlow flows in a distributed matter at each of the compute nodes.
In this post, I will describe a high level overview of some of the already supported features in Dragonflow and our road map moving forward. I will keep this post rather high level and will write detailed posts on each of these features independently.
The following diagram describes the current Dragonflow architecture:
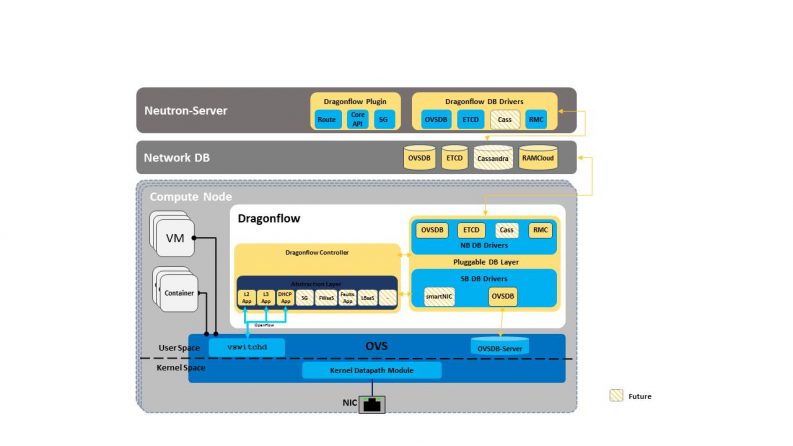
Dragonflow Liberty Release
The following features are already implemented and part of Dragonflow project release for Liberty, you can use this example local.conf to install Dragonflow with devstack on your machine. (Dragonflow has its own devstack plugin.)
L2, Distributed L3 Routing (DVR)
Dragonflow uses OpenFlow to implement both L2 and distributed L3 (DVR) using one bridge (br-int) on each compute host. It is important to note that Dragonflow does not need to use namespaces or any additional agents beside the local controller in order to achieve this.
We have defined and optimized the OpenFlow pipeline which implements L2 and distributes L3 routing in flows.
As connection tracking is being supported in OVS, we also integrate and implement security group rules in flows.
Dragonflow pipeline is optimized to use the OVS megaflow mechanism and is leveraging a hybrid approach of flows installment, meaning that some flows are only installed on demand from the local controller and some are installed proactively. Having this path also opens the door for higher-level reactiveness where the local controller queries the distributed DB or any other external source.
I will do a deeper overview of Dragonflow pipeline in later posts, but we believe that this hybrid approach helps reduce the amount of redundant data that needs to be synced between the compute nodes and is important when plugging external applications to the Dragonflow pipeline.
Pluggable DB Layer
This is one of the more interesting features Dragonflow offers. Dragonflow uses a DB framework to synchronize the virtual network topology and policy from the CMS to all the local controllers; basically, we have a Neutron plugin that translates Neutron model to our DB. The local controllers also register themselves to this DB and create tunnels to one another.
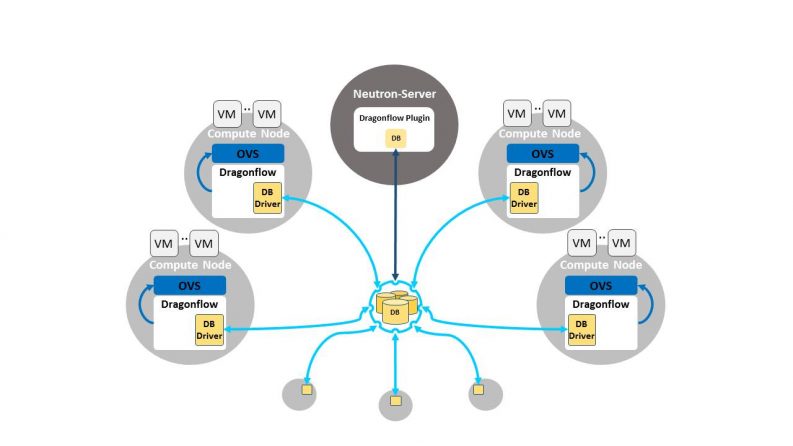
When we designed this area, we decided that building a production-ready DB system takes time, and we also thought that different environments require different DB solutions due to their size, SLA restrictions, and the DB framework overhead on the compute node, latency requirements and more. This is why we designed this layer to be pluggable and use well-known, tested and deployed open source DB solutions.
There is a very lightweight driver API that any new framework that wants to work with Dragonflow needs to implement and a generic installation script, but once this is done, the user can plug Dragonflow to this DB framework and enjoy its features. (Clustering / HA / Performance and latency / ACLs on DB writes and so on).
The DB framework can expose its features using the driver API and the Dragonflow local controller tries to leverage these features if they are supported. For example: support for publish-subscribe, publish-subscribe on specific column values, transactions and more.
The following diagram depicts the DB architecture. Both the plugin and the local controller communicate with a Northbound API adapter layer which is defined in the data model language, and this layer translates the data model to simple key/value DB operations and calls the pluggable DB driver. This is done in order to simplify the creation of new DB drivers and dismiss the need to change them every time a new feature in the Dragonflow data model is added or changed.
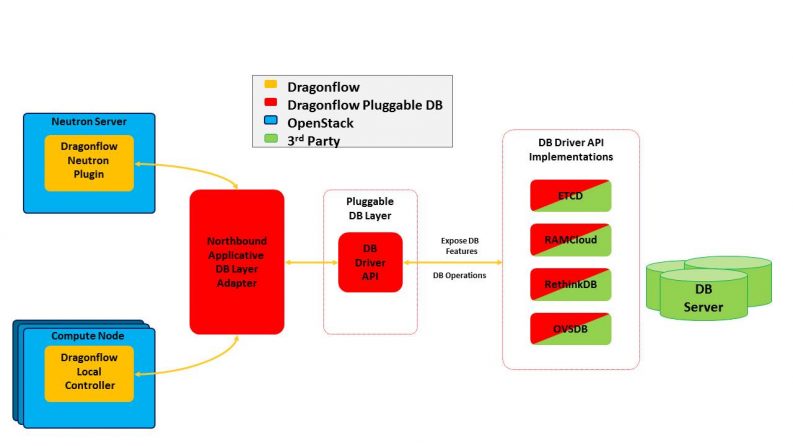
Going forward we have two milestones we want to achieve in this area:
1) Currently all the compute nodes synchronize all the topology and policy data from the DB server; however, we believe that due to the nature of tenant isolation this is not needed. Some virtual ports or VMs can never reach others and all these VMs are spread across the data center. We want to be able to sync the local controller with only the relevant data it needs for its local ports.
2) Future deployments are going to have many more ports due to increased hardware capacity and the excessive use of containers in virtualized environments. This means that in order to scale and provide low latency and good performance, Dragonflow controller must only sync the most relevant data, we believe this can be achieved only with a good cache mechanism and reactiveness to the DB server.
I am planning to write more about this subject and explain our roadmap and milestones better.
Distributed DHCP
The Dragonflow pipeline already supports fully distributed DHCP, and the local controller at each compute node has an internal DHCP application which serves DHCP requests from local VMs. You can read more about this in Eran Gampel Distributed DHCP blog post
Dragonflow Road Map
The following features are still in the design process but are key indicators for our plans and shows that Dragonflow aims to solve and tackle many interesting and useful areas.
Distributed SNAT/DNAT
Distributing DNAT (Floating IPs) is something we are already working on and have a clear and simple design to integrate it in Dragonflow’s current pipeline. For distributing SNAT, we have several ideas but are waiting for additional feedback before we choose one way or the other.
Distributed Network Functions, Topology Injection and Service Chaining
This is an area we have some exciting and interesting ideas. We want to define a way for external applications to be able to manage parts of our OpenFlow pipeline without needing to change the code inside Dragonflow.
We want to allow reactiveness to external applications and be able to define classical service chaining in addition to distributed network service functions in a manner which is easy to manage and deploy.
I will describe this subject more in future posts, so stay tuned.
Smart NICs
Hardware offloading is not a new thing, Todays NICs have embedded switches and flow classification mechanisms that can be used to offload some of the network pipeline computations to hardware. Many companies are already working on fully offloading OVS capabilities to hardware. We see tunneling/encapsulation offloading in the NIC as a major improvement which can already be done today.
We believe it’s impossible for the hardware to keep track with the agility of software and therefore present a hybrid approach of software OVS in addition to hardware capabilities.
In our vision, Dragonflow manages both the local NIC (using its APIs) and a software based OVS and produces an optimized pipeline that is leveraging the NIC hardware capabilities while still using the software OVS for everything else that is not supported in HW. We believe that there needs to be a local controller entity (Dragonflow) that knows to adjust the pipeline correctly depending on the HW capabilities.
We have already started design discussions for a POC with smart NICs vendors.
Hierarchical Port Binding – SDN TORs
Dragonflow is going to support a specific configuration option to allow it to work with VLAN tagging specifying the network segmentation id and have it offload VXLAN tunneling to an "SDN Top Of The Rack" switch.
Containers
Dragonflow is going to support use cases of nested containers inside a VM without the need to introduce another layer of overlay abstraction. We are going to support various different modes to deploy this and have full integration with project Kuryr.
Summary
As you can see we have very challenging and exciting times coming for Dragonflow. We have ambitious plans and want to work on this project with you, we want to share visions and deployment challenges in order to build the best open source solution we can.
If you would like to join us, feel free as we are only at the start. You can take a look at the full code in Dragonflow github and also check our project launchpad page.
You can also join us on IRC at freenode in channel #openstack-dragonflow if you have any questions or suggestions.
Sagie also recently spoke about Dragonflow at the OpenStack Summit Tokyo in the vBrownBags track. Catch the session below to learn more.
This post was contributed by Gal Sagie an open source software architect at Huawei. Superuser is always interested in how-tos and other contributions, please get in touch: [email protected]
Cover Photo // CC BY NC
- What you need to know about Dragonflow for the OpenStack Liberty release - November 5, 2015
- The Hitchhiker’s Guide to the OpenStack Summit Tokyo - October 20, 2015
- Project Kuryr brings container networking to OpenStack Neutron - September 1, 2015










