)
Relax-and-Recover (ReaR) is a pretty impressive disaster recovery solution for Linux. ReaR creates both a
bootable rescue image and a backup of the associated files you choose.

When doing disaster recovery of a system, this Rescue Image plays the files back from the backup and so in the twinkling of an eye the latest state.
Various configuration options are available for the rescue image. For example, slim ISO files, USB sticks or even images for PXEservers are generated. As many backup options are possible.Starting with a simple archive file (eg * .tar.gz), various backup technologies such as IBM Tivoli Storage Manager (TSM), EMC NetWorker (Legato), Bacula or even Bareos can be addressed.
The ReaR written in Bash enables the skillful distribution of Rescue Image and if necessary archive file via NFS, CIFS (SMB) or another transport method in the network. The actual recovery process then takes place via this transport route. In this specific case, due to the nature of the OpenStack deployment, we will choose those protocols that are allowed by default in the Iptables rules (SSH, SFTP in particular).
But enough with the theory, here’s a practical example of one of many possible configurations. We’ll apply this specific use of ReaR to recovera failed control plane after a critical maintenance task (like an upgrade.)
Prepare the undercloud backup bucket
We need to prepare the place to store the backups from the overcloud. From the undercloud, check you have enough space to make the backupsand prepare the environment. We’ll also create a user in the undercloud with no shell access to be able to push the backups from thecontrollers or the compute nodes.
groupadd backup
mkdir /data
useradd -m -g backup -d /data/backup backup
echo "backup:backup" | chpasswd
chown -R backup:backup /data
chmod -R 755 /data
Run the backup from the overcloud nodes
#Install packages
sudo yum install rear genisoimage syslinux lftp -y
#Configure ReaR
sudo tee -a "/etc/rear/local.conf" > /dev/null <<'EOF'
OUTPUT=ISO
OUTPUT_URL=sftp://backup:backup@undercloud-0/data/backup/
BACKUP=NETFS
BACKUP_URL=sshfs://backup@undercloud-0/data/backup/
BACKUP_PROG_COMPRESS_OPTIONS=( --gzip )
BACKUP_PROG_COMPRESS_SUFFIX=".gz"
BACKUP_PROG_EXCLUDE=( '/tmp/*' '/data/*' )
EOF
Now run the backup, this should create an ISO image in the undercloud node (/data/backup/).
sudo rear -d -v mkbackup
Now, simulate a failure xD
# sudo rm -rf /
After the ISO image is created, we can proceed to verify we can restore it from the hypervisor.
Prepare the hypervisor
# Install some required packages
# Enable the use of fusefs for the VMs on the hypervisor
setsebool -P virt_use_fusefs 1
sudo yum install -y fuse-sshfs
# Mount the Undercloud backup folder to access the images
mkdir -p /data/backup
sudo sshfs -o allow_other root@undercloud-0:/data/backup /data/backup
ls /data/backup/*
Stop the damaged controller node
virsh shutdown controller-0
# Wait until is down
watch virsh list --all
# Backup the guest definition
virsh dumpxml controller-0 > controller-0.xml
cp controller-0.xml controller-0.xml.bak
Now, we need to change the guest definition to boot from the ISO file.
Edit controller-0.xml and update it to boot from the ISO file.
Find the OS section, add the cdrom device and enable the boot menu.
<os>
<boot dev='cdrom'/>
<boot dev='hd'/>
<bootmenu enable='yes'/>
</os>
Edit the devices section and add the CDROM.
<disk type='file' device='cdrom'>
<driver name='qemu' type='raw'/>
<source file='/data/backup/rear-controller-0.iso'/>
<target dev='hdc' bus='ide'/>
<readonly/>
<address type='drive' controller='0' bus='1' target='0' unit='0'/>
</disk>
Update the guest definition.
virsh define controller-0.xml
Restart and connect to the guest
virsh reset controller-0
virsh console controller-0
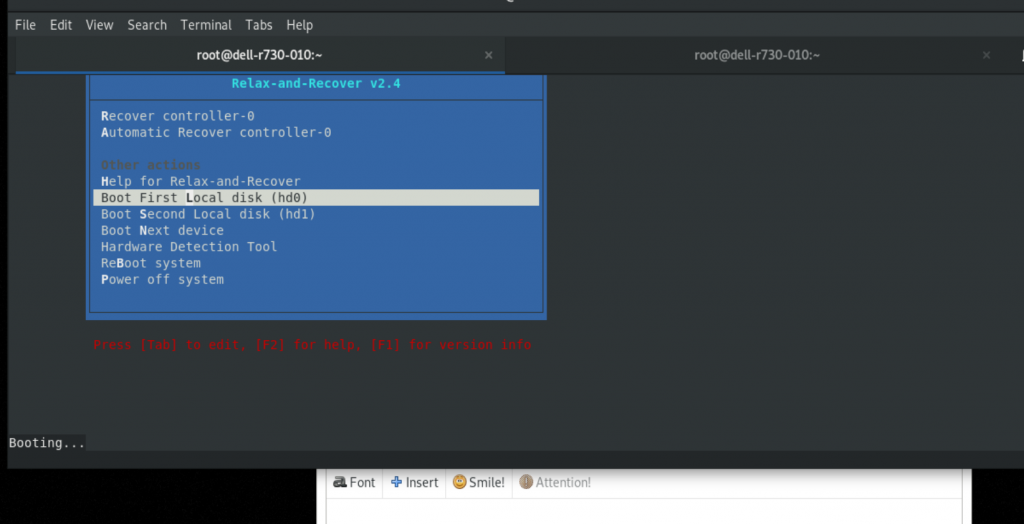
You should be able to see the boot menu to start the recover process. Select “recover controller-0” and follow the instructions.
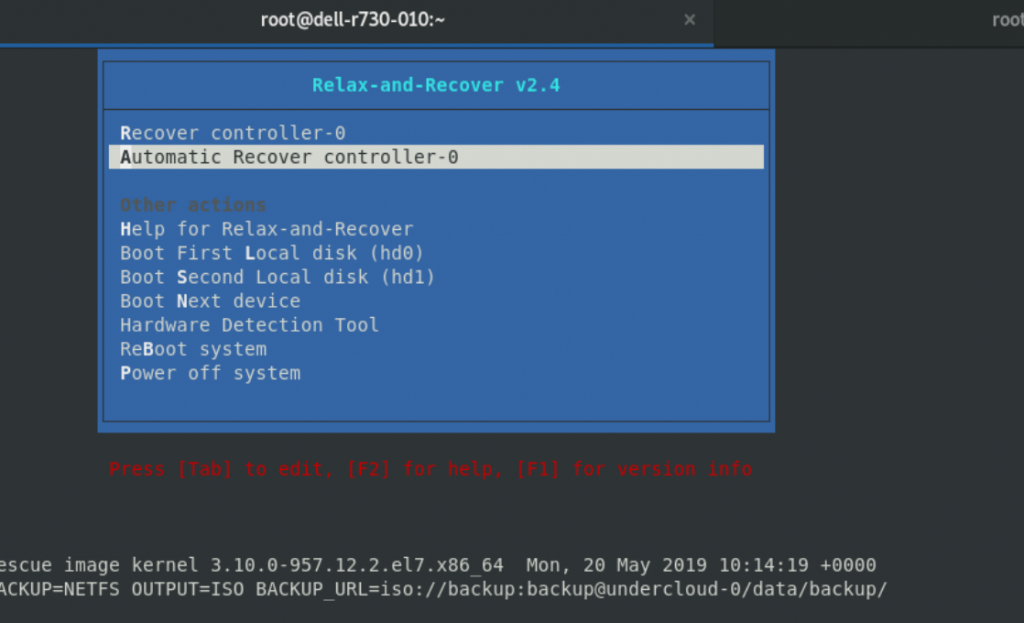
You should see a message like:
Welcome to Relax-and-Recover. Run "rear recover" to restore your system !
RESCUE controller-0:~ # rear recover
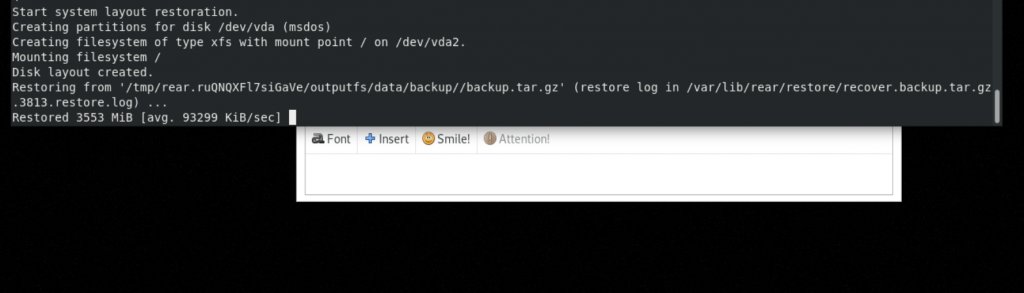
The image restore should progress quickly.
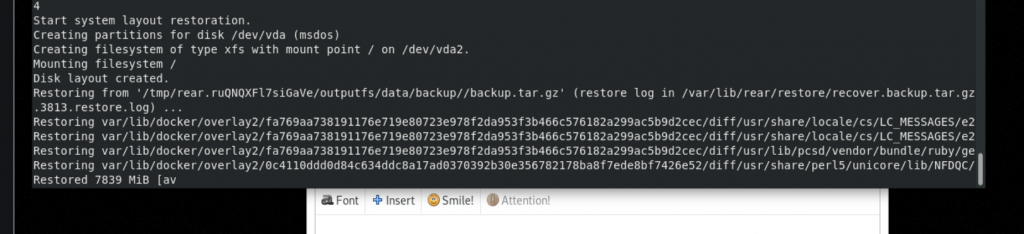
Continue to see the restore evolution.
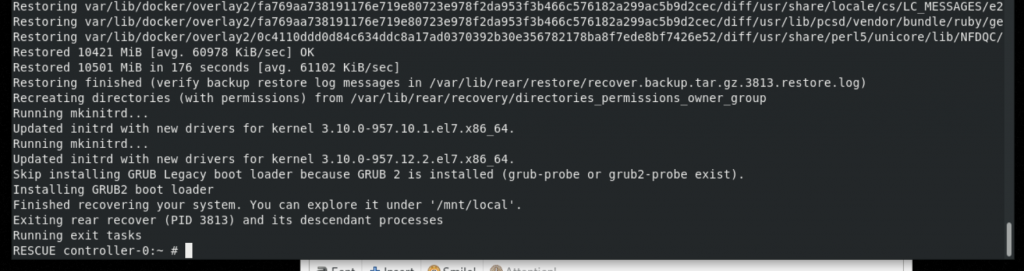
Now, each time you reboot the node will have the ISO file as the first boot option so it’s something we need to fix. In the meantime, let’s check to see if the restore worked.
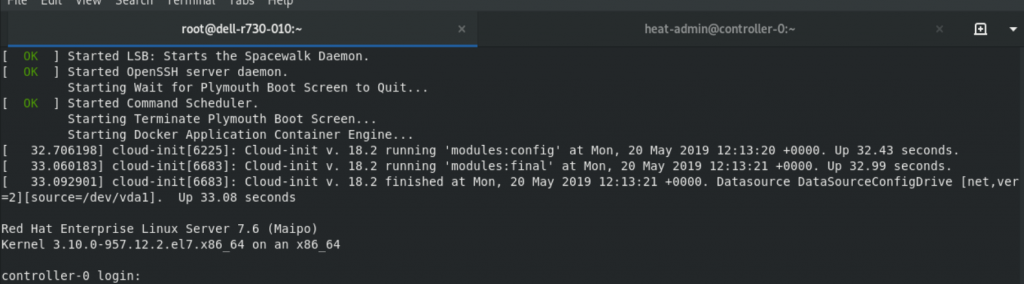
Reboot the guest booting from the hard disk.
Now we can see that the guest VM started successfully.
Now we need to restore the guest to its original definition, so from the hypervisor we need to restore the controller-0.xml.bakfrom the hypervisor
from the hypervisor file we created.
#From the Hypervisor
virsh shutdown controller-0
watch virsh list --all
virsh define controller-0.xml.bak
virsh start controller-0
Enjoy.
Considerations
- Space
- Multiple protocols supported (but we might then to update firewall rules, that’s why I prefered SFTP)
- Network load when moving data
- Shutdown/Starting sequence for HA control plane
- Whether the data plane requires backup
- User workloads should be handled by a third party backup software
Got feedback?
Visit this post’s issue page on GitHub.
Carlos Camacho is a software engineer from Madrid, Spain who works at Red Hat. This post first appeared on his blog.
Superuser is always interested in community content, get in touch: editorATopenstack.org
- Running Relax-and-Recover to save your OpenStack deployment - June 17, 2019
- New TripleO quick start cheatsheet - January 16, 2018







